 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
麻省理工研究出新摄像头技术,搞定了一个自动驾驶的致命性问题(附视频)

用肉眼观察角落另一边的盲区或许不太现实,然而经过科学家们多年研究,已经可以利用专门的激光器实现了。而现在,麻省理工计算科学与人工智能实验室(MIT CSAIL)的研究者们又向前迈进了一步:他们开发了一套成像系统CornerCameras,可以从地面反射的微光中探测到物体。
[video]uu=dfa091e731&vu=1b7b9c1c3a&auto_play=0&width=600&height=450[/video]
这项研究的原理很简单:所有物体都会反射光线,CornerCameras系统能够使用智能手机摄像头采集的视频,实时测量隐藏物体的速度和轨迹。当然,人眼是无法看清这种变化的,但摄像头可以,通过观察角落附近的地面,再根据地面阴影的变化,判断另一边是否有东西在移动。
MIT CSAIL一位发言人说,这项技术有一系列应用场景,包括消防队员在焚烧的建筑物内寻找人,以及自动驾驶汽车探测盲区内的行人等等,在这种应用场景中,它并不需要任何细节,只要知道那边有东西就行了。他还说,这个系统方便的地方在于,可以使用智能手机摄像头采集的视频。
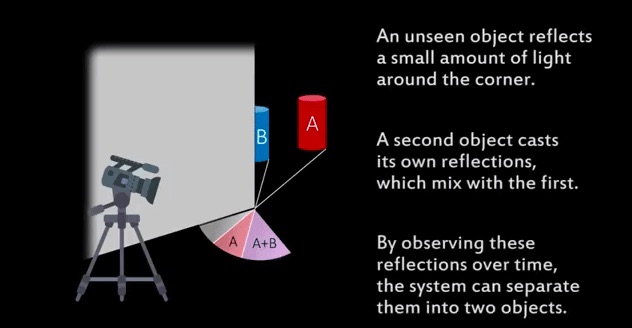
博士毕业生Katherine Bouman是该系统论文的主要作者,她表示,“即使这些‘半影’(模糊的阴影)实际上对于摄像头来说并不可见,我们还是可以通过系统看到它们,以确定它们在哪里,以及它们要去哪里。”
而且,为了观察这种方法对自动驾驶汽车是否可行,她们在阴影角度拍摄了一段远处角落的视频,结果依然能够获得明确的信号。也就是说,即便汽车距离角落很远,也依然能够使用这套系统。
不过,这种方法也存在一些弊端:尽管它可以检测盲区内障碍物的移动速度、位置,但无法辨认该物体的任何细节信息,包括边缘、形状或纹理。相较于激光器的激光反弹原理,这种技术只能检测出在明亮环境下移动的人或物体。而且,用于分析的视频源也必须保持稳定,否则也会出现纰漏。
尽管存在漏洞,但就目前而言,这套系统已经是一项突破了。它在室外明亮光下表现得很出色,甚至在雨中也能工作。
关于雨中作业,Bouman比较惊讶,“由于雨水改变了地面的颜色,所以我认为,系统无法看到光线中千分之一的微小差异。” 不过,“由于系统整合了几十张图像的信息,足以抵消雨滴的影响,所以你可以看到物体的移动。”
CornerCameras系统目前需要一台笔记本来进行必要的图像处理,但Bouman说,这个问题可以在未来得到解决:“从计算角度看,该系统完全可以在手机上运行,只不过我们还没有这么做而已。”

Bouman同麻省理工学院教授Bill Freeman、Antonio Torralba和Greg Wornell共同撰写了这篇论文,Bouman将在本月晚些时候在威尼斯举办的International Conference on Computer Vision(国际计算机视觉大会)上介绍最新工作。
<来源:the Verge;编译:科技行者>


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
