 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
RNN系列教程之二 | 在Python和Theano框架下实现RNN

4.建立基于门控循环单元(GRU)或者长短时记忆(LSTM)的RNN模型
说明:本部分所涉及的相关代码,大家都可以从Github平台获取
-1-语言建模
在这个步骤,我们的目的是使用RNN网络建立和训练语言模型。语言模型的作用是,当我们给出一个由m个单词组成的句子,它可帮助预测下一个单词是什么,包括这一单词出现的概率,也就是条件概率。
![]()
举个例子,“He went to buy some chocolate”这个句子生成的概率,实际上就是给定了“He”这个条件之后出现“went”的概率,乘以给定了“He went”这个条件之后出现“to”的概率,再乘以给定“He went to”这一条件后出现“buy”的概率……以此类推(嗯,有点绕,大家可以多读几遍)。
那么,我们为什么要借助概率预测句子呢?
首先,该语言模型可作为一个评分模型。例如,在机器翻译系统中输入句子,通常会得出多个候选解。在这样的情况下,就可以使用语言模型,选择可能性最大的句子作为输出。
此外,语言模型是一种生成式模型,我们还可以通过给定前面的单词,预测下一个词的概率,并重复该过程,从而生成新的文本。
需要注意的是,上述概率公式中的每个单词的概率都是由它前面所有给定的单词共同决定的。但是由于受计算或内存限制,很难长期存储大量模型。因此,许多模型通常只能关联到前面几个词。
下面具体介绍一下基于RNN进行语言建模的代码实现。
-2-数据训练和预处理
在训练语言模型之前,需要先对数据(即特定文本)进行训练。就像小孩学说话,都是通过大量的词汇练习,才慢慢形成说话习惯。
非常方便的是,这一语言模型的训练通过原始文本就可以实现,不需要对数据做任何人工标记。在这里,我们从 Google's BigQuery 的一个数据集中下载了15,000条Reddit的长篇评论作为文本数据。在此之前,与其它机器学习项目一样,还要先通过预处理将数据转换为正确格式。
2.1分词
如果想要预测每个词的概率,就需要先将原始文本中的每一段文字拆分成句子,再将句子拆分成单词。虽然也可以用空格隔开每段文字,但这种方式无法恰当处理标点符号。例如,“He left!”应分割成3个词:“He”,“left”,“!”。通过NTLK(http://www.nltk.org/)的分词系统中的word_tokenize和sent_tokenize两种方法,可以分别实现对英文的分词和分句。(ps.NLTK也支持中文接口)
2.2过滤低频词
需要注意,在语料库中,很多单词在只出现一到两次,而庞大的词汇表会降低模型的训练速度,除此之外,对于低频词我们也没有足够的上下文信息支持训练,因此,在训练前不妨先删去这些低频词。
在代码中, vocabulary_size代表着词汇的规模(此处我们将大小设置为8000,代表8000个最常见单词,这个数值可以修改)。对于词汇表里没有的单词,我们设置为 UNKNOWN_TOKEN。例如,如果词汇表中没有“nonlinearities”,那么句子“nonlineraties are important in neural networks”就会变为“UNKNOWN_TOKEN are important in neural networks”。在这里, UNKNOWN_TOKEN也是词汇表的一部分,我们会预测它的概率。在生成新文本时,如果预测出来的单词是UNKNOWN_TOKEN,就可以选择用词汇表之外的任一单词来替代它。例如,随机选取词汇表以外的词,或者直接生成句子,直到生成的句子不包含未知词为止。
2.3添加特殊的开始和结束标记
我们在每个句首添加了标签 SENTENCE_START ,句末添加了标签 SENTENCE_END ,以此作为标记来识别模型文本的开头和结尾。
2.4建立训练数据矩阵
在RNN网络中我们的输入都是向量,而非数据集里的字符串。因此,在代码中,需要通过index_to_word和word_to_index两种方法在单词和索引之间创建一个映射,从而把字符串映射成向量。例如,单词“friendly”的索引可能是2001。训练示例 x 可用向量[0,179,341,416]表示,其中0相当于 SENTENCE_START ,相应开始符y为[179,341,416,1]。
我们的目标是预测下一个词,所以 y 是向量 x 的左侧一位,而最后一个词就是SENTENCE_END。也就是说,单词179的正确预测是341,即下一个单词。

下面是文本中的一个实际训练示例:

-3-构建RNN
关于RNN的基本介绍,可以参考本教程的第一篇文章《循环神经网络(RNN)的基本介绍》。
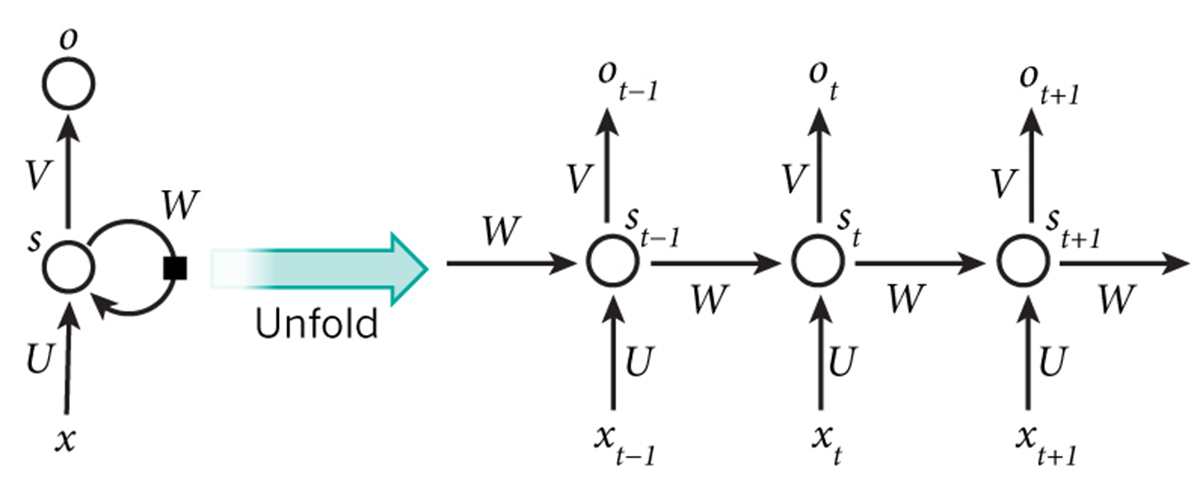
▲RNN的结构图
在RNN中所输入的x是一个单词序列,每个x_t是一个单独的词。但根据矩阵乘法运算原理,我们不能直接使用上述的单词索引表达方法,需要将单词表示为vocabulary_size的实数向量。例如,索引为36的单词均为0,只有第36位为1。所以, x_t是向量,x为矩阵,行即单词。我们将在神经网络代码中进行转换,而非在预处理阶段。类似的,网络的输出o也有类似格式,o_t是vocabulary_size元素的向量,而元素表示句中该单词作为下一个单词出现的概率。
回顾一下教程第一部分中RNN的公式:
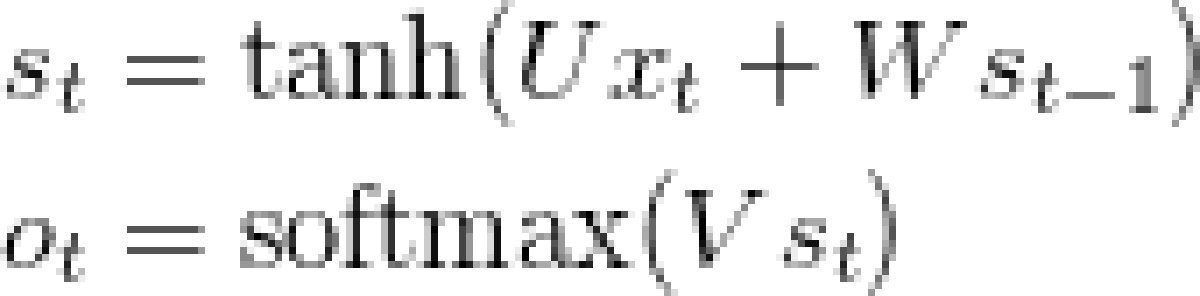
另外,我们还发现,把每一层的矩阵和向量的维度记录下来将非常有助于理解神经网络的结构。在这里,我们假设词汇量C=8000,记忆单元之间的神经元数量(也称之为隐藏层)H=100,它的大小相当于该网络的“记忆容量”,这意味着这个容量越大,学习的模式就越复杂,当然也会增加额外计算量。
下面就是整个结构的大小:
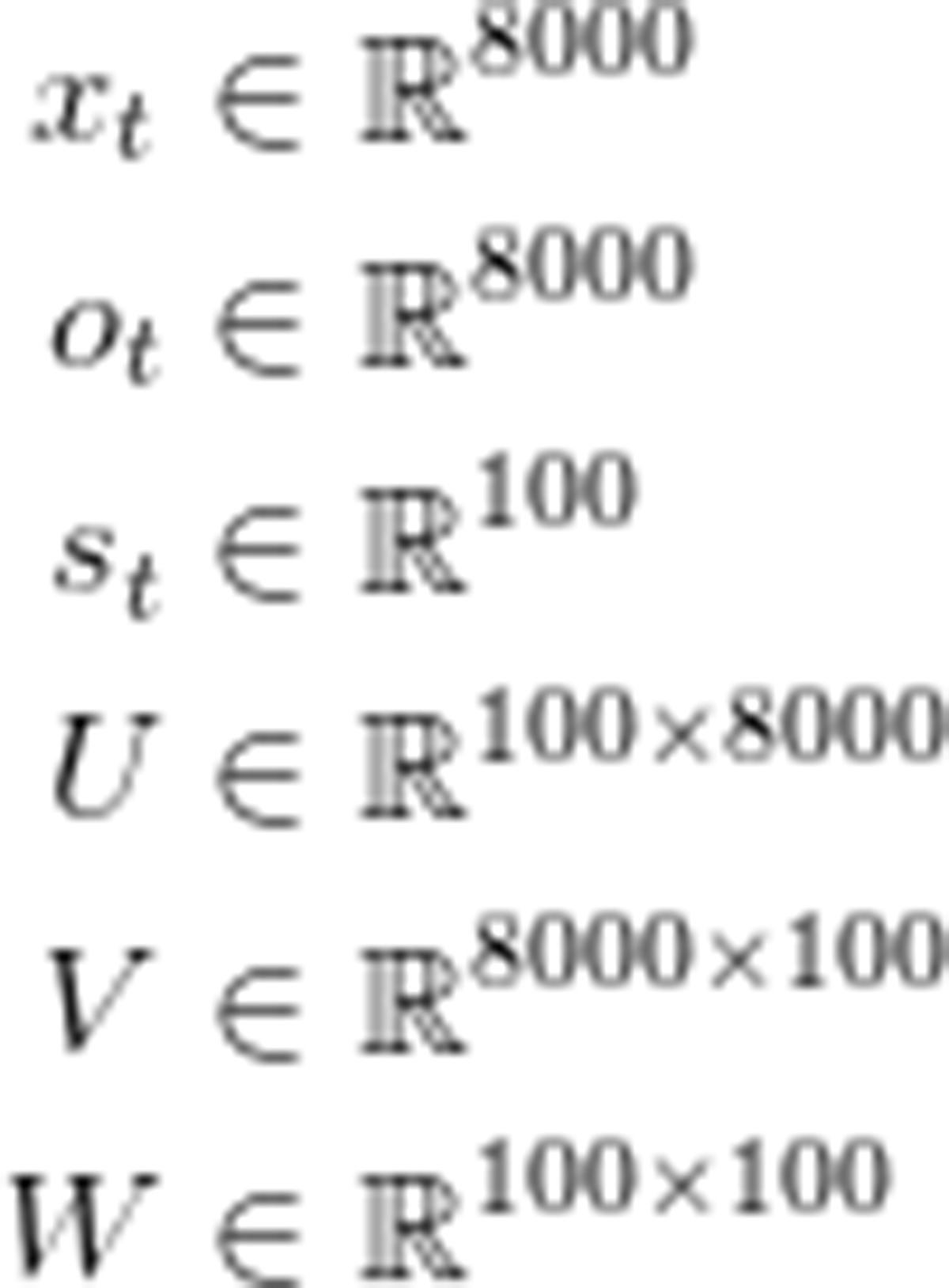
这是非常有价值的信息。U, V和W代表的是神经网络权重参数。因此,我们需要掌握的参数数量为2HC + H^2,在具体的网络中,当C=8000,H=100时,参数值为1,610,000。需要注意的是,实数向量x_t与U相乘,只是一个选择U的column的过程,本质上没什么计算量,所以无需进行完整运算。而该神经网络中最大的矩阵乘积在Vs_t这一步。这也是我们要求词汇表尽量小的原因。
掌握了这些,我们就可以开始实现以下操作:
3.1初始化
先从选择一个初始化所有权重参数的RNN开始,并将其命名为RNNNumpy,后面还会有一个Theano版本。初始化U, V和W有些复杂,不能简单将其初始化为0,这将造成所有层级的对称运算。非常重要的是,因为初始化数值会对最后的训练结果产生影响,所以必须进行随机初始化。
该领域的大量研究表明,初始化的最佳效果由激活函数(此处指tanh)决定。用等距随机抽样的方式,以范围![]() 中上一层的传入连接数n为间距来初始化权重,这是比较好的方法。尽管看似复杂,但无需过于担心,只要将参数初始化为小的随机值,通常都可以正常运行。
中上一层的传入连接数n为间距来初始化权重,这是比较好的方法。尽管看似复杂,但无需过于担心,只要将参数初始化为小的随机值,通常都可以正常运行。
下面是代码:
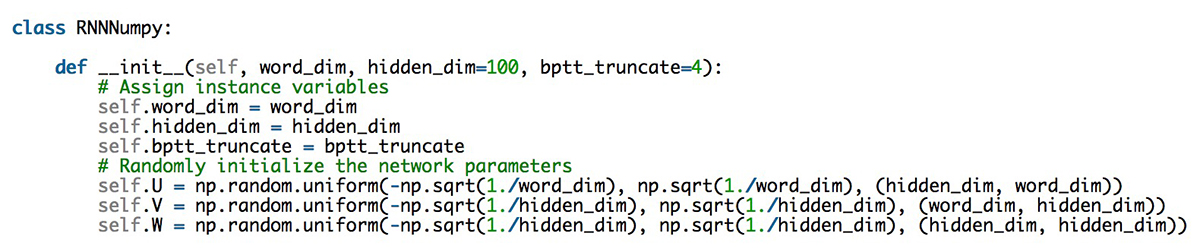
在上面的代码中,word_dim表示词汇量的大小,hidden_dim表示隐藏层(可自行选择)的大小。另外还有bptt_truncate参数。
3.2前向传播过程
接下来,介绍一下前向传播算法如何实现(用于预测词的概率):

值得注意的是,为了避免二次运算,在这个函数的最后,不仅仅返回了输出层,还返回了隐藏层,从而来计算梯度。在这里,每一个o_t都表示一个8000维的单词概率向量,代表每一个单词的输出概率。在模型评估过程中,我们想得到的往往只是概率最大的单词,所以,在下面,我们将用一个predict函数来实现:

来试试我们全新的实现方法,看一下它的输出示例:
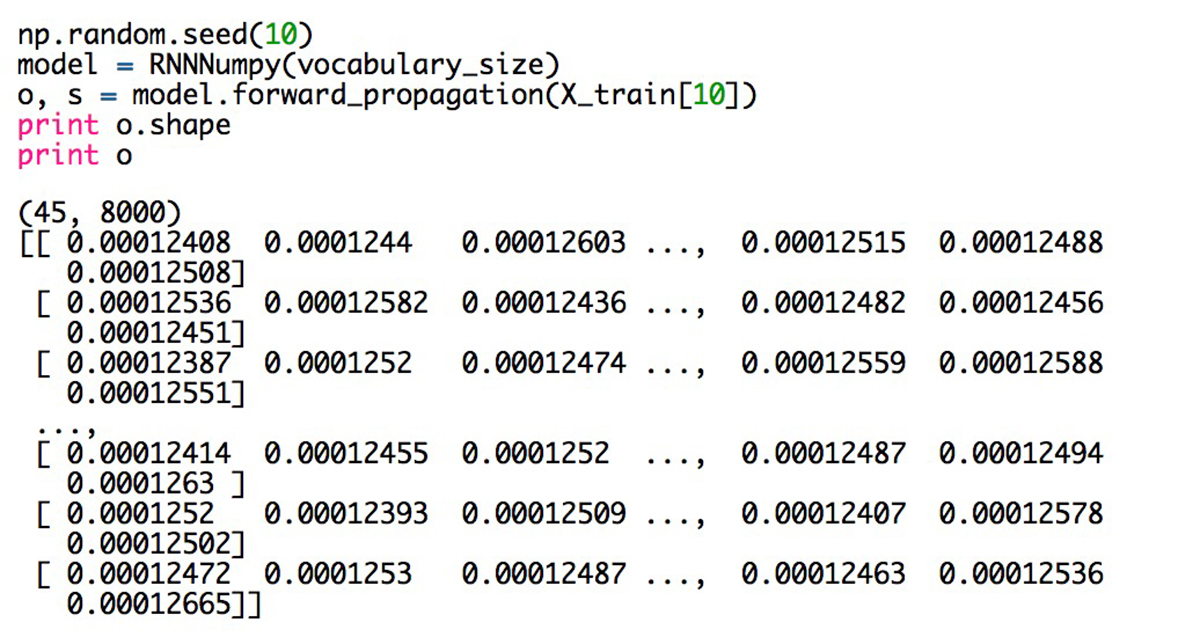
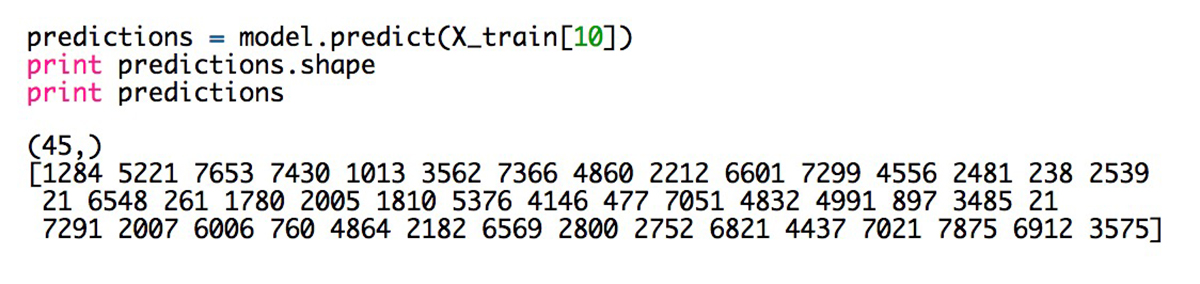
对于句子中的每一个单词(图中的句子有45个单词),我们的模型输出了8000个数值,对应词典中每一个单词可能作为句子中下一个单词出现的概率。由于已将U,V,W初始化为随机值,这些预测是完全随机的。下面列出了每个单词的最高预测概率的索引:
3.3计算误差
为训练该神经网络,需要通过一种方法量化误差,目的是找到能将训练数据的误差最小化的最优U,V,W参数,我们将这种方法称为损失函数L。通常我们会选择一个称为cross-entropy loss(交叉熵损失函数)的损失函数。假设有N个训练样本(文本中的单词)以及C个类别(词汇量的大小,8000),预测输出o和实际标注y的损失函数如下所示:
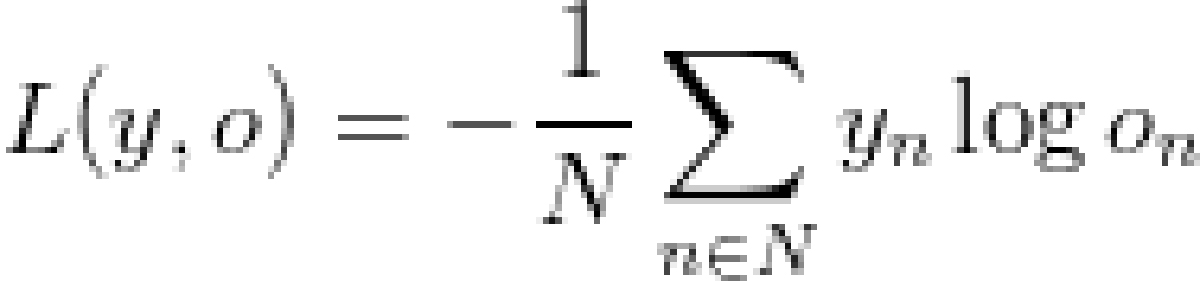
这个公式看似复杂,但其实就是对训练样本求和后再与预测损失相加。y(实际标注值)与o(预测输出值)相距越远,误差就越大。因此,我们采用calculate_loss函数来实现:
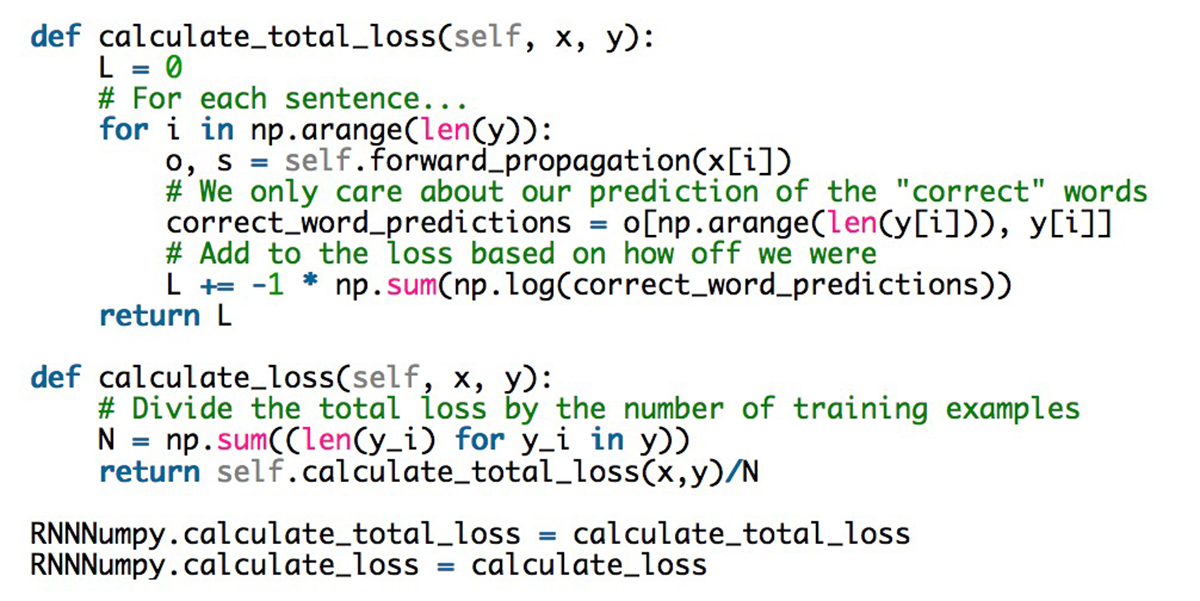
倒退一步再思考一下随机预测的误差是多少。我们将得到一条底线并确认该实现是正确的。词汇中有C个单词,每个单词的(平均)预测概率应为1/C,由此公式得出误差值:

结果很接近了!但需明确,计算整个数据集的损失将非常消耗时间,如果数据量过于庞大,会花费数个小时。
3.4 SGD与BPTT训练下的RNN模型
别忘了,我们要寻找的是能将训练数据的总损失最小化的U,V,W参数。最常用的做法是SGD(Stochastic gradient descent),即随机梯度下降算法。SGD的原理非常简单,通过对所有训练样本进行迭代,并在每次循环操作中,不断调整参数从而降低错误率,这些方向均由损失的梯度给出: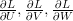 。
。
在这个过程中,我们需要一个学习率( learning rate)来决定SGD在每次迭代中前进多少(学习率越大,学习速度越快,但容易“穿越“,导致找不到最优解;学习率越小,学习速度越慢)。这个算法不仅仅能够用于神经网络,在许多其他机器学习算法中,SGD也有大量的应用。
那么,如何计算上文提到的梯度呢?在传统的神经网络中,我们通过反向传播算法来计算。而在RNN中,在此基础上我们还会做简单修正,使用BPTT(Backpropagation Through Time )来实现,用中文来解释,就是跨越时间的反向传播算法。为什么要用这样的方法?是由于在这个模型中,所有参数实时共享,这造成每次输出的梯度不仅取决于当前时刻的数值,也取决于之前所有时刻的数值。因此,在这里我们将应用链式法则。
现在,我们可以先把BPTT算法(在下一篇教程中我们会对此做更详细的介绍)看做一个黑匣子,下面来看一下代码实现,当我们输入训练示例(x,y)时,就会输出三个梯度,用于更新权重:

3.5梯度检验
通常我们会建议同时应用反向传播算法和梯度检验,因为这是检验正确性的一种方式。梯度检验背后所暗含的,是与某一时刻公式斜率相同的参数的导数,而可以稍微改变参数,也可通过余数相除获得。
当你在实现一个反向传播算法的时候,可以同时做一个梯度检查,来检验你的算法是否正确。检查的背后原理也很简单,就是从导数的定义出发,公式如下:
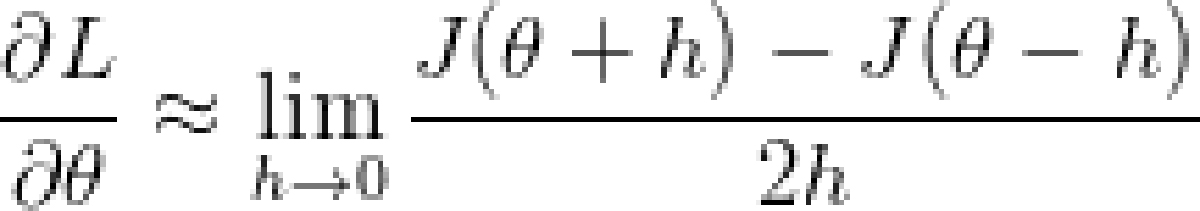
下面是实现代码:


3.6应用SGD
有了上面的准备工作,我们就可以使用SGD算法来更新权重了。可以用两个步骤来实现:第一,sdg_step方法,即在一个batch上更新权重,它可以计算参数,并且每完成一次批处理,便完成一次更新;第二,用外循环来遍历所有的训练样本,并动态更新学习率。下面是实现代码:

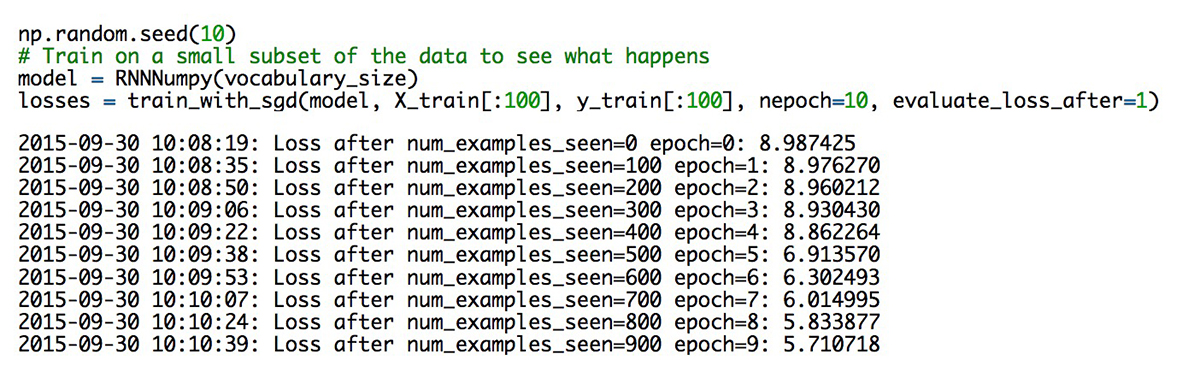
完成!尝试这样训练网络的耗时如下图:

可以看到,在我的电脑上,要完成SGD算法的实现,大概需要花350毫秒。而在我们的训练样本大约有80,000个,如果每完成一个周期(整个数据集的迭代)要花几个小时,完成几个周期可能会花几天,甚至几周。
幸运的是,有很多种方法可以提高代码速度。比如,可以一直使用同一个模型来提高代码运行速度,或者可以改变模型减少计算消耗时间,当然也可以双管齐下。研究人员已经找到许多方法减少模型的计算耗时,比如说他们会使用分层级的softmax函数或者增加项目层,以避免大规模的矩阵乘法。
此外,通过使用GPU也可以提高运算速度。但这之前,我们还是需要通过使用小数据集尝试运行SGD算法,从而检验误差是否真的减小了。
-4-用Theano和GPU训练神经网络
我们编写了一个基于Theano的RNN实现程序代码,从而代替numpy。同本文其他代码一样,这个代码可以在Github上获取。

这一次,使用Mac,我们每完成一个SGD只花费了70毫秒,比最开始的速度提高了15倍,这意味着只需要费几小时或者几天就可以完成对模型的训练。当然,尽管我们的模型现在已经足够好了,但是依然有很多值得改进的地方。
以下是我自己预训练的Theano模型的使用方法:

-5-生成文本
在有了模型之后,可以利用它生成新文本:
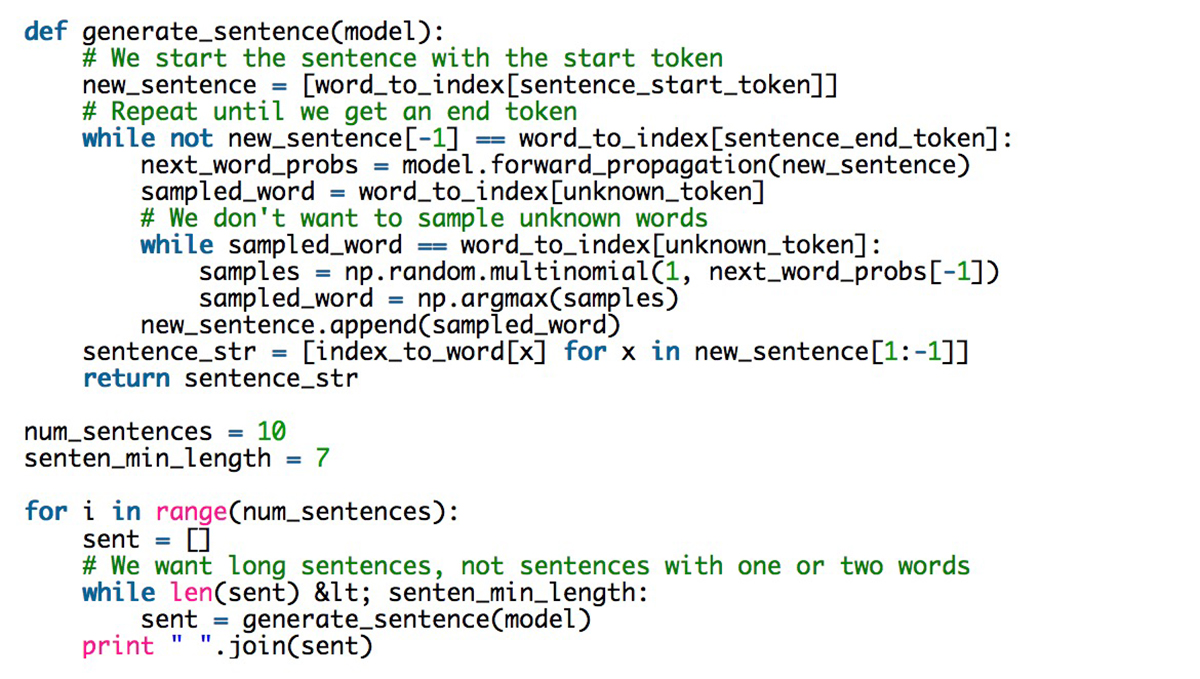
以下我们挑选了几个生成的句子:
Anyway, to the city scene you’re an idiot teenager.
What ? ! ! ! ! ignore!
Screw fitness, you’re saying: https
Thanks for the advice to keep my thoughts around girls.
Yep, please disappear with the terrible generation.
值得注意的是,虽然在以上这些句子中,模型非常成功的运用了句法学习,恰当的使用了逗号(通常在and和or中间),以句号作为结尾。有时,它还模仿了很多网络用语,比如使用惊叹号和笑脸符号。然而,许多生成的句子要么没有意义,要么有一些语法错误(我确实选择了里面最好的句子)。一部分原因可能是因为我们的神经网络训练的时间不够长,或者训练的数据不够多,但是这不是主要原因。
最主要的原因在于,传统的RNN模型无法学习两个相隔较远的单词间的依赖性和相关性,所以不能生成有意义的文本。这也是为什么RNN模型刚被研发出来时无法被普遍推广的原因。理论上它们很完美,但实际上不能被很好的应用,并且短时间内找不到原因。
当然,也不用过分担心,现在我们已经找到了很多更好的方式来训练RNN模型。
另外,需要说明的是,本文涉及的算法也可以应用于LSTM和其他的RNN模型中。
| 来源:WILDML;作者:Denny Britz;编译:科技行者


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

AWS AI实验室发布EvalAgent:让AI自动给AI写"成绩单",但这件事比想象中难得多
AWS AI Labs研究团队发布EvalAgent,这是一套通过"评估技能"自动生成AI智能体评测方案的系统,将首次运行成功率从17.5%提升至65%,并在人类专家评测中获得79.5%的偏好选择。

给暗夜照片"开灯":亚历山大大学研究团队如何让AI用"深度感知"还原黑暗中的真实色彩
亚历山大大学提出M2Retinexformer,通过融合深度、亮度和语义三种辅助模态,让AI在增强暗光图像时兼顾几何结构与视觉自然度。

浙江大学与西湖大学联手破解AI模型适配难题:无需反向传播,一次正向扫描搞定任务适配
浙大、西湖大学等联合提出FAAST,无需反向传播,一次正向扫描将训练样本压缩为快速权重矩阵,推理时间和内存占用分别节省90%和95%以上。

慕尼黑工业大学造了一个"考官":用后见之明来测试AI医生,结果几乎全不及格
慕尼黑工业大学发布RealICU基准,用专家后见之明评测大语言模型在ICU实时决策中的真实能力,发现现有顶级AI存在有害推荐率过高和锚定偏差两大安全隐患。

AWS AI实验室发布EvalAgent:让AI自动给AI写"成绩单",但这件事比想象中难得多

给暗夜照片"开灯":亚历山大大学研究团队如何让AI用"深度感知"还原黑暗中的真实色彩

浙江大学与西湖大学联手破解AI模型适配难题:无需反向传播,一次正向扫描搞定任务适配

慕尼黑工业大学造了一个"考官":用后见之明来测试AI医生,结果几乎全不及格
