 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
RNN系列教程之三 | 基于时间的反向传播算法和梯度消失问题

4.建立基于门控循环单元(GRU)或者长短时记忆(LSTM)的RNN模型

http://neuralnetworksanddeeplearning.com/chap2.html
-1-时序反向传播算法 (BPTT)
先来快速回忆一下RNN的基本方程。注意,为了和要引用的文献保持一致,这里我们把o改成了![]() 。
。
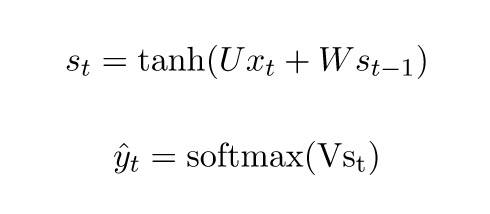 同样,将损失函数定义为交叉熵损失函数,如下所示:
同样,将损失函数定义为交叉熵损失函数,如下所示:
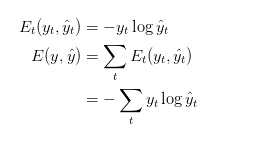
在这里,y_t是表示的是时间步t上的正确标签,![]() 是我们的预测。通常我们会将一个完整的句子序列视作一个训练样本,因此总误差即为各时间步(单词)的误差之和。
是我们的预测。通常我们会将一个完整的句子序列视作一个训练样本,因此总误差即为各时间步(单词)的误差之和。
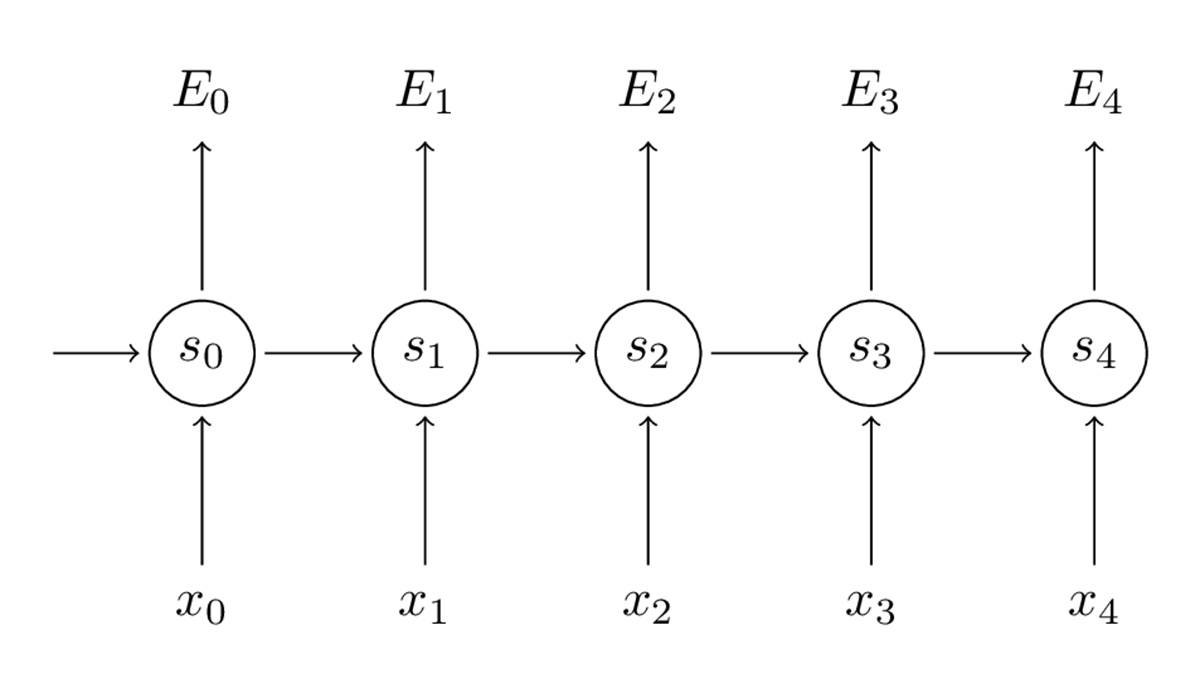
▲RNN反向传播
别忘了,我们的目的是要计算误差对应的参数U、V和W的梯度,然后借助SDG算法来更新参数。当然,我们统计的不只是误差,还包括训练样本在每时间步的梯度:
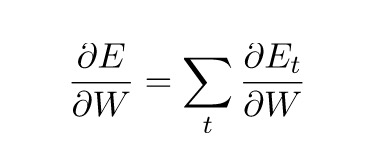

▲RNN的结构图
我们借助导数的链式法则来计算梯度。从最后一层将误差向前传播的思想,即为反向传播。本文后续部分将以E3为例继续介绍:
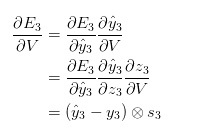
由上可知,z_3 =Vs_3,![]() 为两个矢量的外积。为了让大家更好理解,这里我省略了几个步骤,你可以试着自己计算这些导数。我想强调的是,
为两个矢量的外积。为了让大家更好理解,这里我省略了几个步骤,你可以试着自己计算这些导数。我想强调的是,![]() 的值仅取决于当前时间步的值:
的值仅取决于当前时间步的值:![]() 。有了这些值,计算参数V的梯度就是简单的矩阵相乘了。
。有了这些值,计算参数V的梯度就是简单的矩阵相乘了。
但![]() 有所不同。我们列出如前文所示的链式法则来解释原因:
有所不同。我们列出如前文所示的链式法则来解释原因:
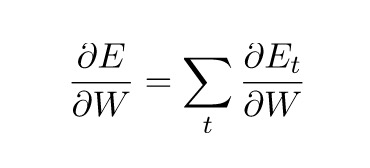
▲链式求导式子1
其中,s_3 = \tanh(Ux_t + Ws_2) 取决于s_2,而s_2则取决于W和s_1,以此类推。因此,如果要推导参数W,就不能简单将s_2视作常量,需要再次应用链式法则,真正得到的是:
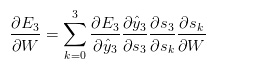
▲链式求导式子2
上面的式子用到了复合函数的链式求导法则,将每个时间步长对梯度的贡献相加。换言之,由于参数W时间步长应用于想要的输出,因此需从t=3开始通过所有网络路径到t=0进行反向传播梯度:

▲BPTT复合函数链式求导
5个时间步梯度的递归神经网络展开图
请注意,这与我们在深度神经网络中应用的标准反向传播算法完全一致。主要区别在于我们对每时间步的参数W的梯度进行了求和。传统的神经网络(RNN)中,我们不在层与层之间共享参数,也就无需求和。但就我而言,BPTT不过是标准反向传播在展开RNN上的别称。好比在反向传播算法中,可以定义一个反向传播的delta矢量,例如:基于z_2 = Ux_2+ Ws_1的 。和传统的反向传播算法一样,我们仍然可以定义残差,然后计算梯度。
。和传统的反向传播算法一样,我们仍然可以定义残差,然后计算梯度。
直接实现BPTT的代码如下:
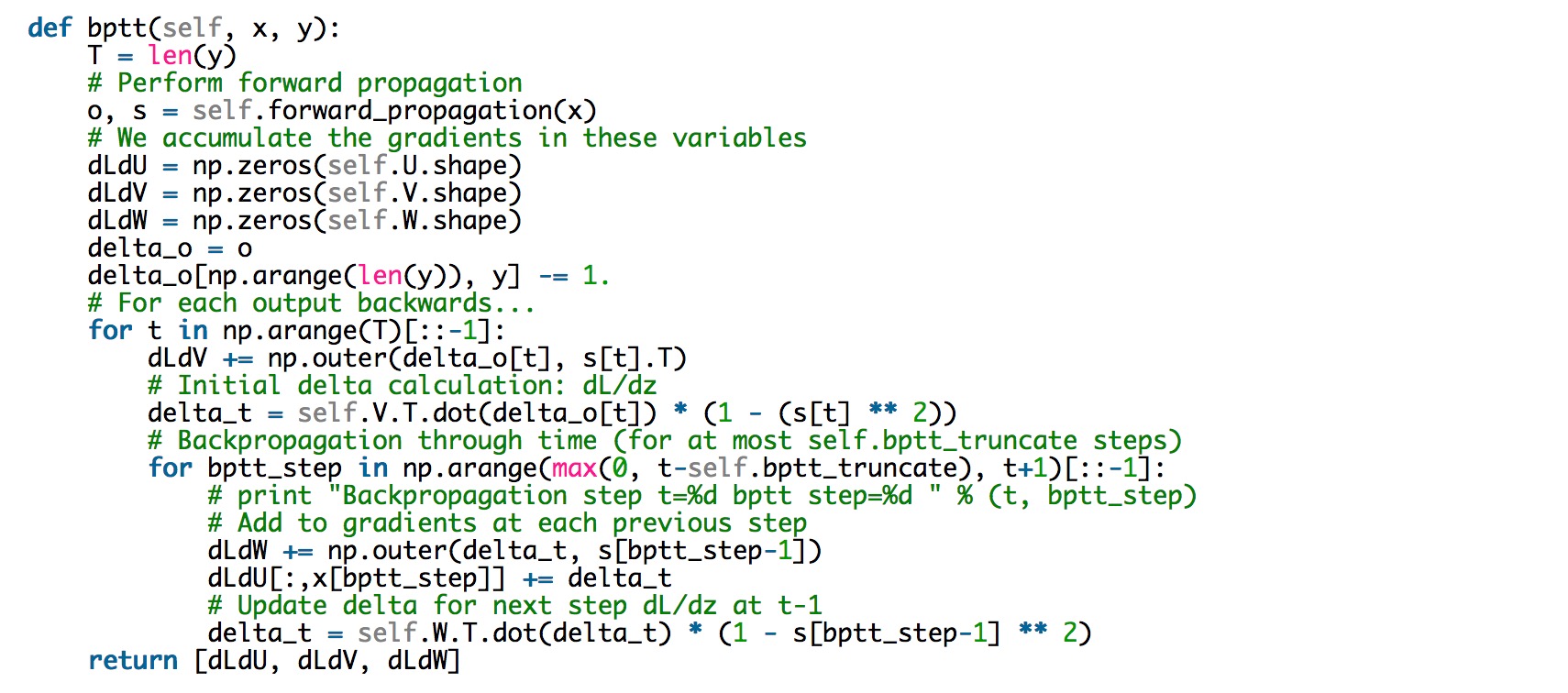
该代码解释了难以训练RNN的原因:因为序列(句子)很长,可能由20个或以上单词组成,因此需反向传播多层网络。在实际操作时,许多人会在反向传播数步后进行截断成比较长的步骤,正如上面代码中的bptt_truncate参数定义的那样。
-2-梯度消失问题
本教程的前面章节提到过RNN中,相隔数步的单词间难以形成长期依赖的问题。而英文句子的句意通常取决于相隔较远的单词,例如“The man who wore a wig on his head went inside”的语意重心在于一个人走进屋里,而非男人戴着假发。但普通的RNN难以捕获此类信息。那么不妨通过分析上面计算出的梯度来一探究竟:

别忘了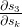 本身为链式法则!例如,
本身为链式法则!例如, 。还要注意,我们在对向量函数的向量求导,结果是一个矩阵(名为雅可比矩阵),所有元素均为逐点的导数。因此,上述梯度可重写为:
。还要注意,我们在对向量函数的向量求导,结果是一个矩阵(名为雅可比矩阵),所有元素均为逐点的导数。因此,上述梯度可重写为:

然而,上述雅克比矩阵中2范数(可视为绝对值)的上限是1(此处不做证明)。直观上,tanh激活函数将所有的值映射到-1到1这个区间,导数值也小于等于1(sigmoi函数的导数值小于等于1/4):
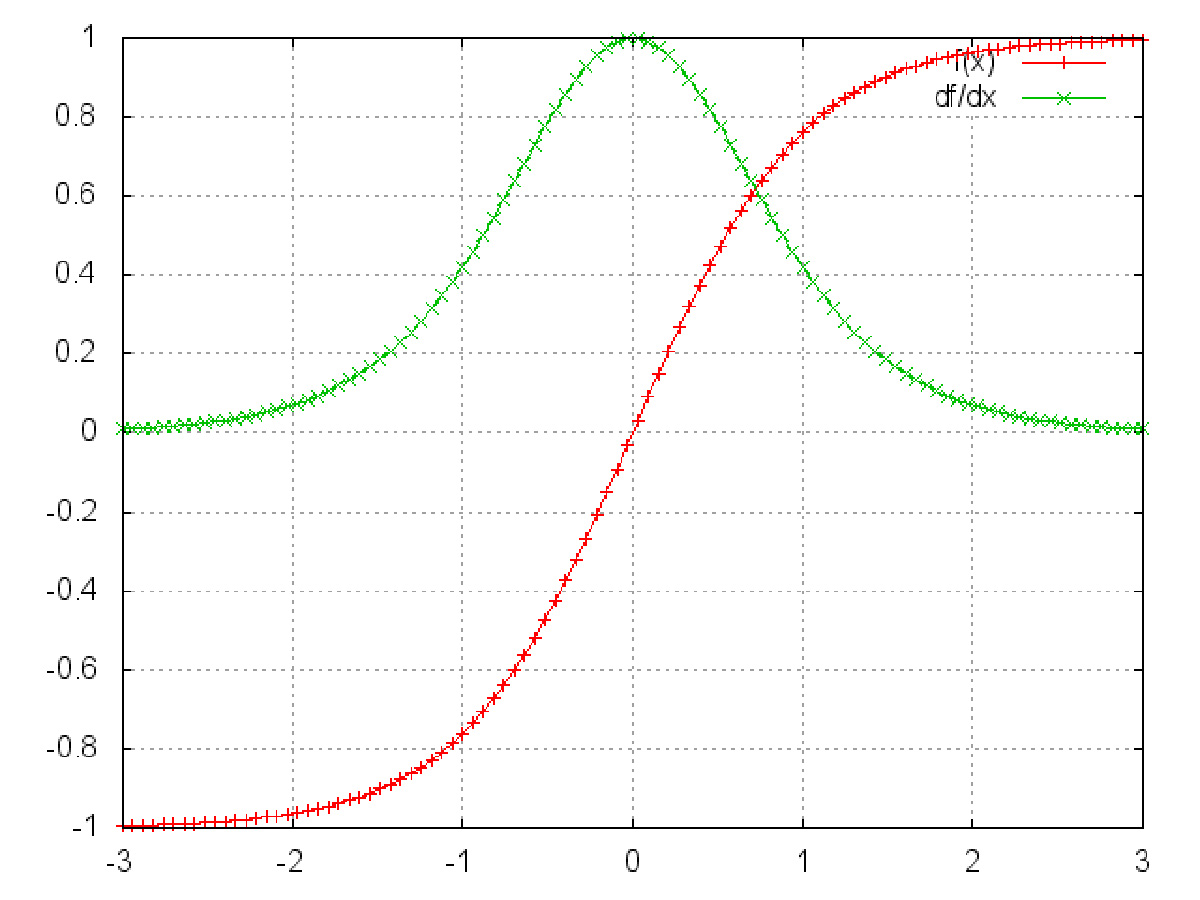
▲tanh及其导数。图片源自:http://nn.readthedocs.org/en/rtd/transfer/
可以看到tanh和sigmoid函数在两端的导数均为0,近乎呈直线状(导数为0,函数图像为直线),此种情况下可称相应的神经元已经饱和。两函数的梯度为0,使前层的其它梯度也趋近于0。由于矩阵元素数值较小,且矩阵相乘数次(t - k次)后,梯度值迅速以指数形式收缩(意思相近于,小数相乘,数值收缩,越来越小),最终在几个时间步长后完全消失。“较远”的时间步长贡献的梯度变为0,这些时间段的状态不会对你的学习有所贡献:你最终还是无法学习长期依赖。梯度消失不仅存在于循环神经网络,也出现在深度前馈神经网络中。区别在于,循环神经网络非常深(本例中,深度与句长相同),因此梯度消失问题更为常见。
不难想象,如果雅克比矩阵的值非常大,参照激活函数及网络参数可能会出现梯度爆炸,即所谓的梯度爆炸问题。相较于梯度爆炸,梯度消失问题更受关注,主要有两个原因:其一,梯度爆炸现象明显,梯度会变成Nan(而并非数字),并出现程序崩溃;其二,在预定义阈值处将梯度截断(详情请见本文章)是一种解决梯度爆炸问题简单有效的方法。而梯度消失问题更为复杂,因为其现象不明显,且解决方案尚不明确。
幸运的是,目前有一些方法可解决梯度消失问题。合理初始化矩阵 W可缓解梯度消失现象。还可采用正则化方法。此外,更好的方法是使用 ReLU,而非tanh或sigmoid激活函数。ReLU函数的导数是个常量,0或1,因此不太可能出现梯度消失现象。
更常用的方法是借助LSTM或GRU架构。1997年,首次提出LSTM ,目前该模型在NLP领域的应用极其广泛。GRU则于2014年问世,是LSTM的简化版。这些循环神经网络旨在解决梯度消失和有效学习长期依赖问题。相关介绍请见本教程下一部分。
| 来源:WILDML;作者:Denny Britz;编译:科技行者


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
