 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
谷歌AI也有输的时候,麻省理工学院学生让它狗和果酱傻傻分不清楚

CNET科技行者 1月4日 北京消息(编译/高玉娴):人类能够从照片中轻松辨认出可爱的小狗,但谷歌公司的神经网络看到的却可能是牛油果酱。这样一个看似有趣的“恶作剧”背后,实际上隐藏着巨大的风险。

如今,机器学习算法已经成为人工智能发展的关键要素,然而,事实证明算法也存在着被攻击的风险和挑战。
以著名的“认猫”实验为例,即使面对一张明显显示为猫的图像时,一旦其中存在“对抗性示例”,机器学习算法所识别的结果可能将不再是猫,而是人眼所无法检测到的某些刻意安排的内容。
虽然此前许多研究人员认为,这类攻击方式只存在于理论层面,即更像是一种示例而非真实威胁。然而,来自麻省理工学院学生社区LabSix的一群学生们已经证明并发表了相关论文,表示他们能够创建出误导算法的三维对象(对抗性示例)。

如上图,这个3D打印的龟被系统识别为步枪。
这一操作的实现方式是利用算法生成对抗性示例,并在模糊、旋转、缩放或翻译等转换过程中导致目标错误分类。
而最近,该团队又宣布,这样的“误导”已经可以在“黑盒”条件下进行。即不需要了解算法的内部运作机制,也可以创建对抗性示例,从而攻击算法。
这意味着已经全面渗透至人们日常生活的人工智能技术正面临着新的挑战。试想一下,有人可以利用这样的方式使用对抗性示例代替你本人来解锁你的智能手机或付款。
在最新的论文当中,该团队仍以谷歌Cloud Vision API(这是一种目前已经广泛使用的标准商业化图像分类算法)为例,描述了如何在对算法知之甚少的前提下创建对抗性示例的过程。
他们对于Cloud Vision的所有认知皆来自对其图像分类结果的分析,例如其在识别图像时给出的几个最佳选项,以及各个选项对应的概率。
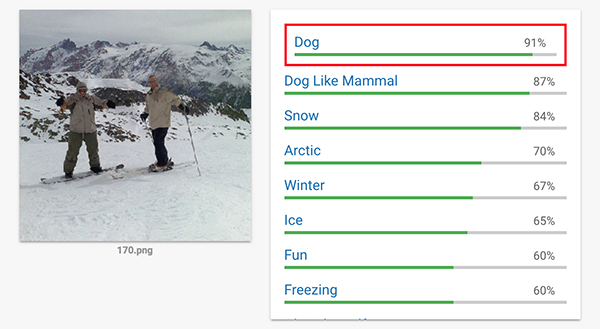
LabSix的一名学生Andrew Ilyas表示,在不具备关于神经网络基础信息的前提下攻击算法确实是一项巨大的挑战。他指出:“以识别狗的实验为例,一般大家在构建这类对抗性示例时,首先想到的是如何从狗的形象出发将其转变为牛油果酱。从传统角度来思考,最重要的是随时获得算法将该图片内容辨别为牛油果酱的概率。然而在攻击谷歌Cloud Vision时,算法并不会告诉我们任何将图片判断为狗或牛油果酱的具体概率,只会展示其对于狗这一结论的肯定程度。”
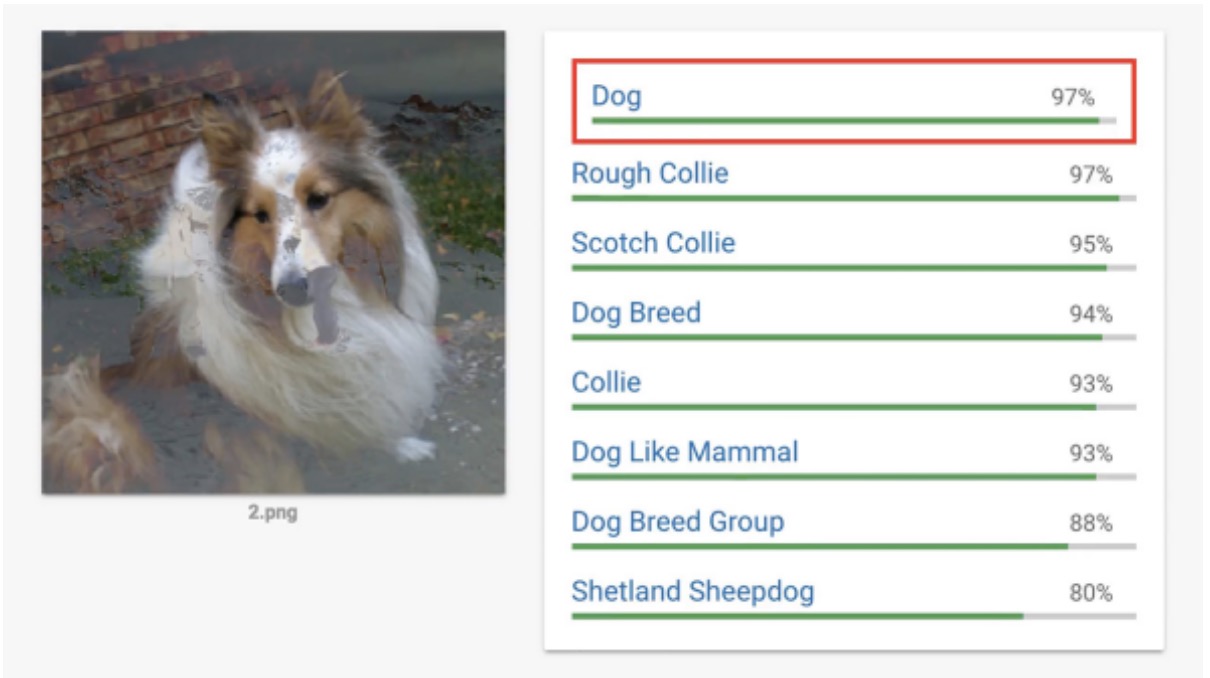
▲图片来源: LabSix
为了解决这个问题,该团队使用了另一个算法,用来估算能够让机器将狗的图片误认为是牛油果酱过程,所需要变化的像素值,然后再利用两套算法共同对像素进行缓慢切换。即从目标类的图像(在此实验中指的是狗的图像)开始,逐渐将其转化为期望的对抗图像(在此实验中指的是牛油果酱的图像),同时在输出中保持目标类。在所有的时间里,这个算法只保留了破坏像素的正确组合,让系统认为它是在看着一只狗。
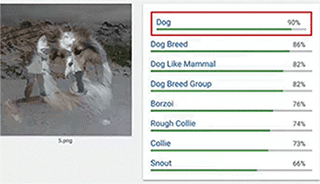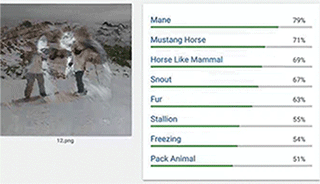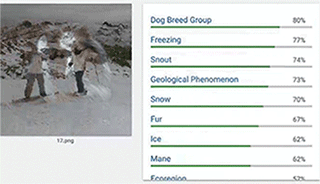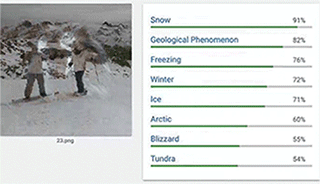
▲如上图:目标类图像是狗,对抗图像是双人雪橇
该流程的工作原理在于,算法会将该图像数千次甚至上百万次地提交至Cloud Vision API,从而测试何时才会成功将识别结果由狗转变为牛油果酱或其它事物。

▲图片来源: LabSix
这一过程通常需要经过超过500万次的查询,但Ilyas和他的团队使用了称为自然进化策略(NES)的计算机算法,从而帮助他们猜测图像识别是如何对图像进行分类的。作为结果,他们只进行了大约100万次查询就为谷歌Cloud Vision的图像分类器创建出了一个特定对抗性示例。而人眼在观看图片时,永远无法从中看到任何牛油果酱的端倪。
Ilyas说,之所以可以做到这一点,是因为他们的程序会在图像上调整大量的像素,而不是每次都是几个像素。
此外,在另一项测试中,他们还成功地让谷歌的API误将一架直升飞机认作一组步枪。
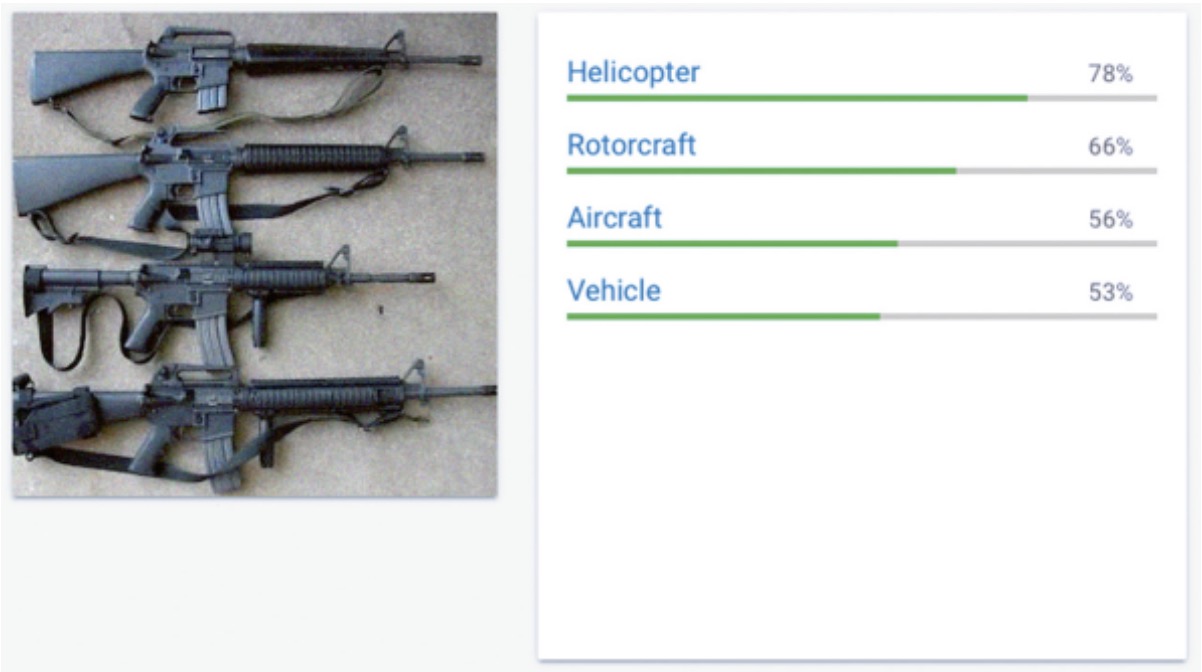
▲图片来源: LabSix
这种攻击谷歌系统的方法提供了一个真实的例子,说明基于人工智能的图像识别系统是如何被黑客入侵的。这一发现有着更为广泛的意义。举例来说,国防企业与刑事调查人员也在利用基于云的机器学习系统对大量图像进行分拣。熟练的编程人员将能够制作一张看似正常的图像,但机器在进行读取时却可能出错——反之亦然。
LabSix团队的另一名学生Anish Athalye表示:“我们正在向着攻克实际系统的方向探索,而这显然会给真实存在的系统带来挑战,因为事实证明即使是商业化、封闭性质的专有系统,也同样很容易受到攻击。”
虽然到目前为止,他们只尝试了谷歌的系统,但据团队指出,他们的技术在其他图像识别系统上应该也可以运行。
如今,随着对抗性示例逐步进入大家的视线,研究人员们也开始意识到自己还没有找到强有力的方法予以防范。这可能代表着其会在未来带来破坏性的后果。对此,Ilyas与Athalye表示,好在研究人员能够在这些技术传播得过度广泛之前发现这一漏洞,并有机会抢在恶意人士之前对其加以修复。
来源:Fast Company
编译整理:科技行者


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Snowflake AI挑战传统语言学:万千茫茫文字中,LLM真的只是"随机鹦鹉"吗?
这项由Snowflake AI Research发表的研究挑战了传统语言学对大型语言模型的批评,通过引入波兰语言学家Mańczak的理论框架,论证了LLM的成功实际上验证了"频率驱动语言"的观点。研究认为语言本质上是文本总和而非抽象系统,频率是其核心驱动力,为重新理解AI语言能力提供了新视角。

Yale大学团队推出"免费博士劳工":让AI研究助手像真人团队一样工作的革命性框架
freephdlabor是耶鲁大学团队开发的开源多智能体科研自动化框架,通过创建专业化AI研究团队替代传统单一AI助手的固化工作模式。该框架实现了动态工作流程调整、无损信息传递的工作空间机制,以及人机协作的质量控制系统,能够自主完成从研究构思到论文发表的全流程科研工作,为科研民主化和效率提升提供了革命性解决方案。

德国马普所团队发明"智能大脑重新布线"技术:让AI专家模型学会即时调整自己
德国马普智能系统研究所团队开发出专家混合模型的"即时重新布线"技术,让AI能在使用过程中动态调整专家选择策略。这种方法无需外部数据,仅通过自我分析就能优化性能,在代码生成等任务上提升显著。该技术具有即插即用特性,计算效率高,适应性强,为AI的自我进化能力提供了新思路。

聊天机器人怎么不在线聊天中"迷路"?Algoverse AI研究团队的熵值导航新突破
Algoverse AI研究团队提出ERGO系统,通过监测AI对话时的熵值变化来检测模型困惑程度,当不确定性突然升高时自动重置对话内容。该方法在五种主流AI模型的测试中平均性能提升56.6%,显著改善了多轮对话中AI容易"迷路"的问题,为构建更可靠的AI助手提供了新思路。

Snowflake AI挑战传统语言学:万千茫茫文字中,LLM真的只是"随机鹦鹉"吗?

Yale大学团队推出"免费博士劳工":让AI研究助手像真人团队一样工作的革命性框架

德国马普所团队发明"智能大脑重新布线"技术:让AI专家模型学会即时调整自己

聊天机器人怎么不在线聊天中"迷路"?Algoverse AI研究团队的熵值导航新突破
