 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
埃森哲推出AI测试服务,深度学习算法的“黑匣子”问题或将不再
现如今,AI的智能、自主及高效程度又来到了一个发展高潮,成为人类完成日常工作、改善生活、提升幸福感的得力助手。但同时,由于是人类赋予了AI系统自主决策的能力,因此,许多人开始提出,人类需要对AI“负责”。
如何负责?其中包括三大核心,即问责制、责任制和透明度。这三点构成了AI的A.R.T原则。
- 责任制指的是人们在研发、生产、销售和使用AI系统的过程中所承担的工作,也包括AI系统为人类制定决策、识别错误等过程中承担意外结果的能力。
- 问责制,即解释个人行为并对其负责的能力。比如,无人驾驶汽车碰撞行人的责任应由谁承担?是传感器、制动器等硬件的设计者?是自主驾驶软件的设计师?是批准无人驾驶汽车上路的权力机关?还是个性化设置汽车决策制定系统的车主?显然,汽车是产品,其自身无法承担责任,但一切利益攸关方都难逃其咎。因此,基于问责原则,理想的模型和算法应该赋予AI系统以解释其自主制定决策依据的能力。
- 透明度,即诠释、检查和展示AI系统诸多运行机制的义务,涉及制定决策、适应环境、使用和管理已生成数据等方面。如今AI算法基本都是“黑匣子”。因此,我们需研发检验AI算法及其结果的方法。此外,还需采用透明的数据管理机制,确保合理透明地收集、生成和管理用于训练算法和制定决策的数据,同时减少偏见,强化数据隐私及安全。
然而,当前的大部分算法虽然高效,却缺乏透明度。为此,许多专家和机构正在不断研究,希望能够提高对深度学习算法的透明度和可解释型。比如,谷歌一直呼吁的就是“公平而负有责任”的AI研发。
对此,不久前普华永道(PwC)公布了一个“负责任的AI框架(Responsible AI framework)”,强调了专用AI提高结构性能,提高AI透明度的重要性。

▲Responsible AI framework
该框架包括了四大部分:战略、设计、发展及AI的运行:
- “战略”:强调了是要将AI的创新能力与企业核心战略目标和绩效指标相结合,以及人为干预在AI系统运行过程中的重要性;
- “设计”:则重点提出了要“打开”AI的“黑匣子”,普华永道认为,缺乏透明度会造成固有声誉和一定的财务风险,因此确保软件设计尽可能透明且可审计,这一点非常重要。同时,它提出,最有效的“控制”是在设计和实施阶段建立的,可以引入“行为抑制程序”或“对抗模型”,用以监测AI技术的适应性和准确性标准;
- “发展”:重新梳理计划管理、管理数据的依赖性、用足够的时间进行测试和训练、设置置信度阈值;
- “运行”:一方面要认识到高质量数据的关键作用,预防数据带来的无意的“偏见”,另一方面则要预防系统性风险,防范有意的攻击。
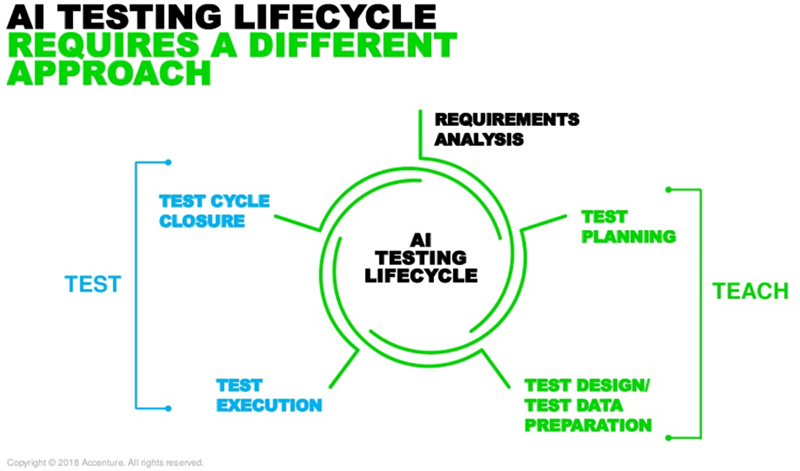
此外,另一咨询公司埃森哲近日也透露,企业将很快能为AI系统提供专门的测试服务。通过其推出的AI测试服务,企业能够利用自身的基础设施或云计算建立可靠的AI系统,并进行监控和测量。此外,还包含面向团体机构的测试策略、工程、数字和企业技术。
埃森哲技术服务集团首席执行官Bhaskar Ghosh表示:“企业在推动创新和发展的过程中,见证了转变的价值,因此正加速推广AI。随着AI融入各企业,为确保其安全和质量,避免对企业业绩、品牌声誉、规则等造成负面影响,寻求更佳的方式训练维持这些系统,就变得至关重要。”

通过“教学与测试”方法,将确保AI系统以两种不同方式作出正确决策:
“教学”阶段负责检测用于训练机器学习所选用的数据、模型和算法,统计评估不同模型以达成最佳的生产模式的同时,遵守道德规范,避免性别、种族等偏见。
“测试”阶段将对比AI系统的所有输出结果与企业内部的关键性能指标,评估系统是否能解释某决策或输出的依据。埃森哲表示,为维持系统性能,该阶段采用了创新技术与云计算工具持续监测系统。
一家金融服务公司曾用该方法训练了会话虚拟客服。据该公司称,其训练速度较之前提升了80%,客户推荐服务的准确率高达85%。不仅如此,它还被用于训练情绪分析解决方案,评估某品牌的服务水平。
埃森哲高级管理总监兼战略及全球测试服务负责人Kishore Durg表示:“AI测试系统仍面临着一些挑战。传统应用程序测试的预设场景数量有限,因此结果不太可靠。而AI系统需要的是无限量的测试方法。因此,我们还需掌握数据评估、模型学习、算法选择、偏见监测及遵从道德法规等能力。”
无论如何,我们看到随着AI的应用前景愈发明朗,越来越多的利益相关方和企业正着眼于解决AI算法的“黑匣子”问题。我们也相信,一旦这一问题得以解决,AI 技术在企业中的创新与应用将出现一个质的飞跃。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
