 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
DeepMind找到了破解深度学习黑匣子的方法
因为对神经网络深层功能的理解,不仅有助于我们了解其决策机制,同时我们构建更为强大的人工智能系统也至关重要。
中,也解释了他们如何通过逐一删除单个神经元的方式去理解和判断神经网络的性能。他们认为,理解神经科学与深度学习神经网络之间关联性的重要方法之一,正是调查个体神经元的作用,特别是那些易于解释的神经元。
研究人员开发了专门的图像分类模型,然后逐一删除其中几个神经元,从而测量每个删除对模型结果的影响。
据DeepMind称,他们的发现产生了两个结果:
- 虽然以往的众多研究都集中于理解易于解释的单个神经元(例如'猫神经元',或者深层网络内隐藏层中的神经元等等只会对猫的图像产生反应的单元),但结果显示,它们在重要性上并不比综合且难以解释的神经元更高;
- 能够对从未见过的图像进行正确分类的神经网络,在神经元缺失适应性方面要比只能够对已经见过的图像进行分类的网络强。有点拗口,我们换句话来说,也就是适应度更高的网络比单纯依靠记忆起效的网络更能摆脱对单一神经元的依赖。
"神经元可能较易解释,但其重要性尚不明确
研究人员广泛分析了只能对单一输入图像类别作出响应,且易于解释的神经元(即“选择性”神经元)。他们发现,在深度学习当中,此类神经元包括了"猫神经元"、情绪神经元以及概括神经元; 而在神经科学领域,此类神经元则包括Jennifer Aniston神经元等。然而,这些仅占少数比例的高选择性神经元在重要性上到底与其它低选择性、更令人费解且难以解释的神经元有何区别,目前还不得而知。
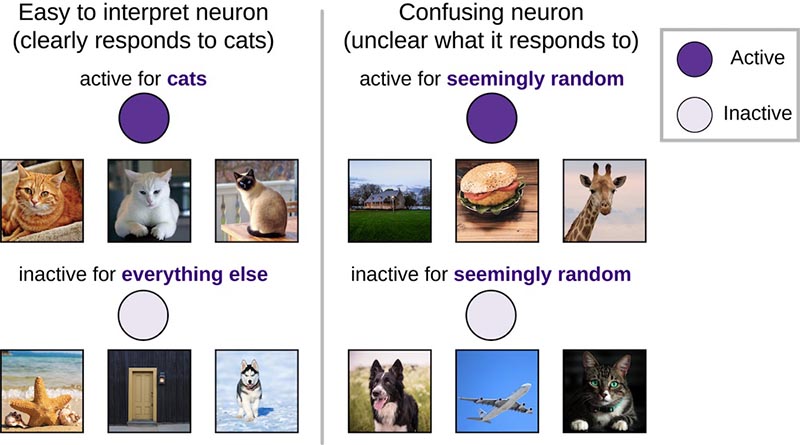
具有清晰响应模式的神经元(例如对猫的图像活跃,但对其它图像皆不敏感的神经元)比综合性的神经元(即能够对各类随机图像集发生反应的神经元)更易于解释
而为了评估神经元的重要性,研究人员在测试当中移除了部分神经元,从而观察网络的分类任务处理效能所发生的变化。如果其中某个神经元非常重要,那么将其移除就会产生极大的破坏性,并显著降低网络效能。相反,如果移除的神经元并不太重要,那么就不会造成什么影响。
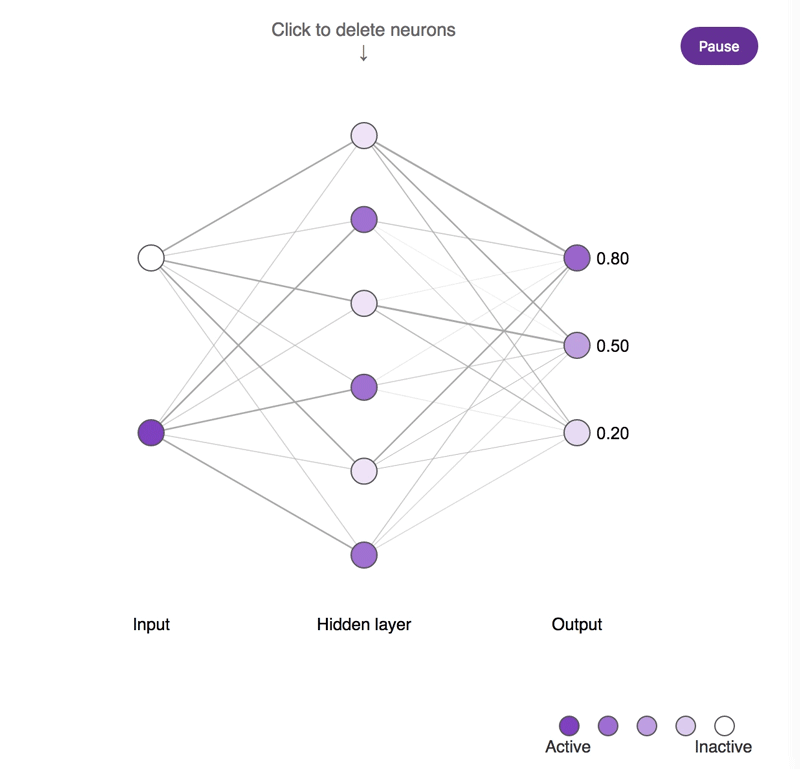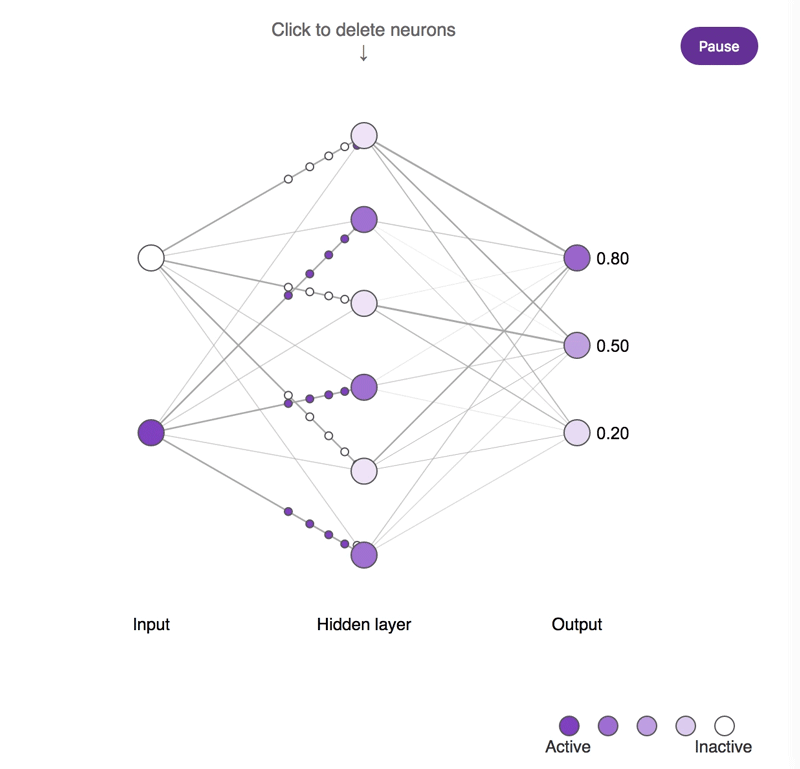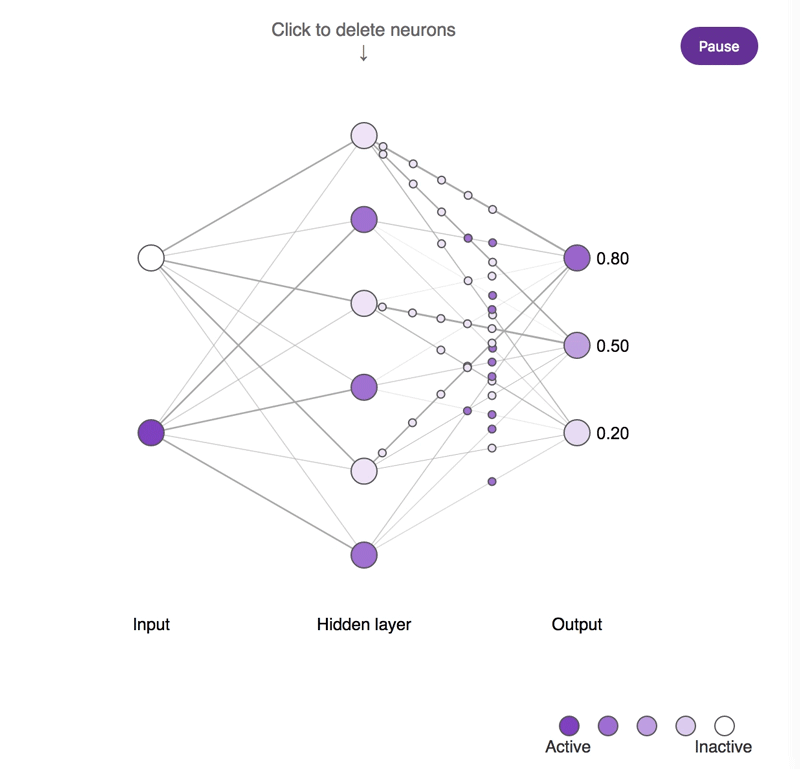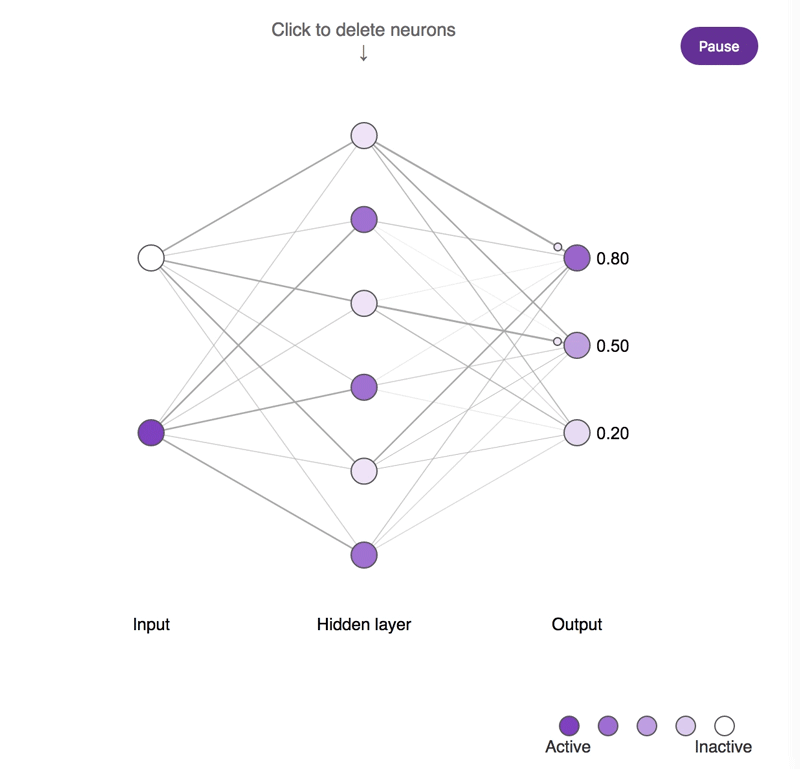
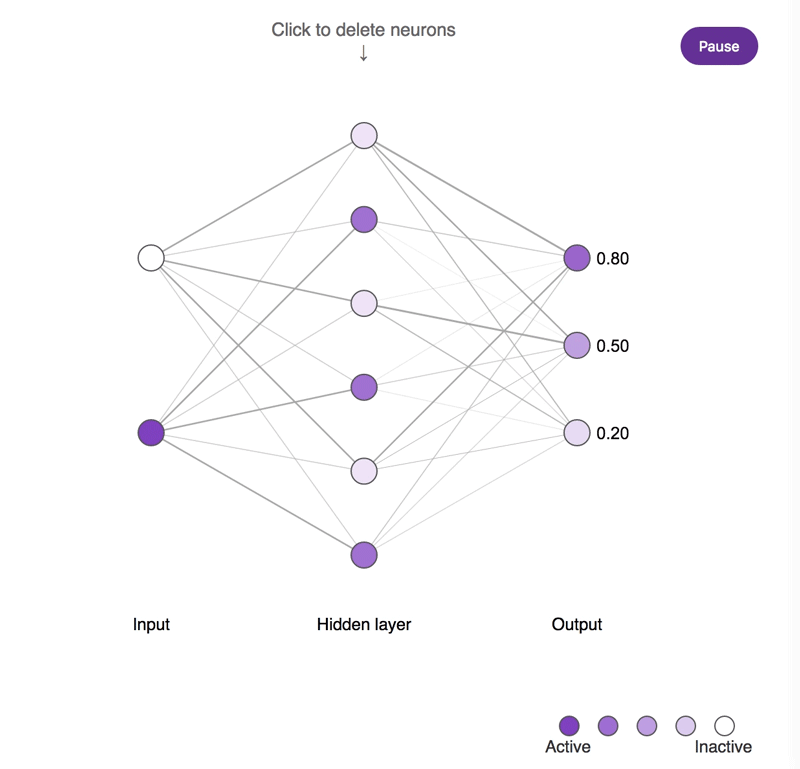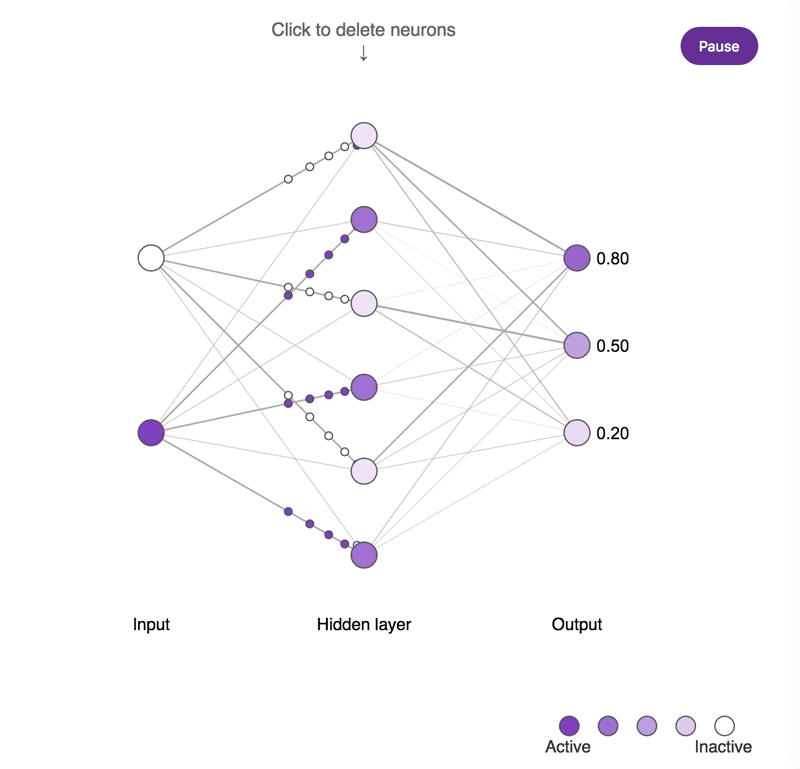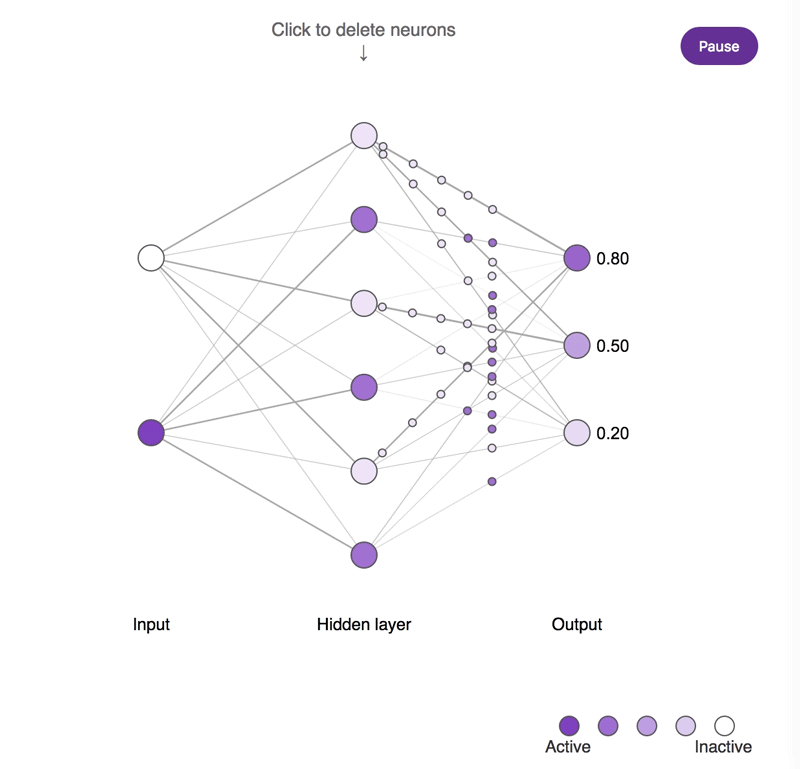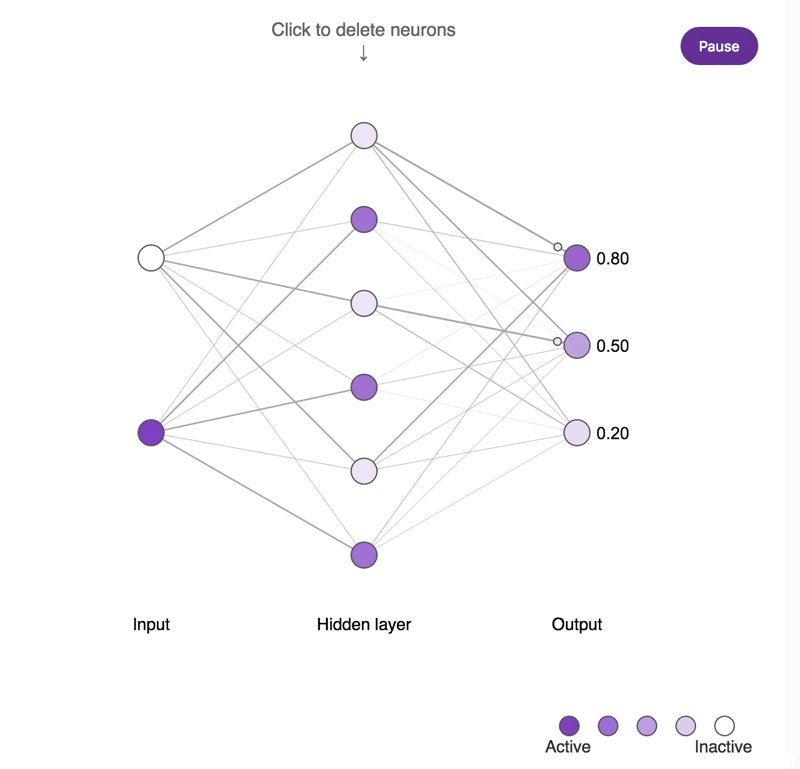
神经元缺失对简单神经网络所造成影响的概念示意图。较深的神经元往往更为活跃。尝试点击隐藏层神经元并将其移除,观察输出神经元的活动所发生的改变。需要注意的是,移除一个或两个神经元对输出结果的影响很小,而移除大部分神经元则会产生显著的影响,并且其中一部分神经元确实比其它神经元更为重要!
这一发现与最近在神经科学方面的研究进展相互印证,目前科学家们已经证明那些作用不明的神经元实际上能够提供丰富的信息。这意味着我们必须迈过易解释神经元这道难关,才有可能真正搞清楚深层神经网络的运作机制。
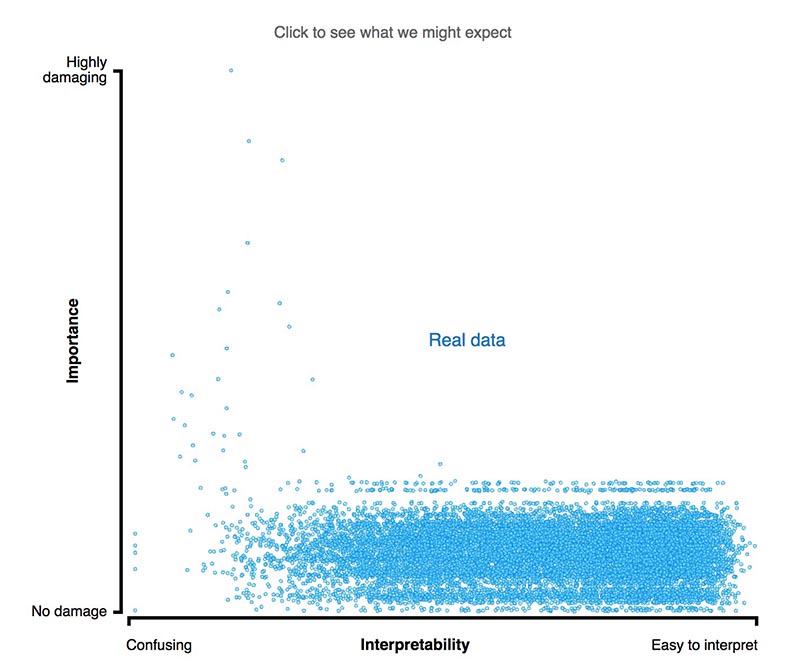
虽然"猫神经元"可能更易于解释,但其重要性并不比综合性且不具备明确偏好的神经元更高。可以点击图中标记,看看重要性与解释性之间到底存在着怎样复杂的关系
因此,研究人员的结论是,尽管可解释神经元在直觉上更易于理解(比如"它喜欢狗"),但其重要性并不一定会比缺少明显偏好的综合性神经元更高。
推广能力更强的网络也具有更大的弹性
举例来说,如果一套图像分类网络只能对以前见过的特定小狗图片进行分类,却无法对新的小狗图像完成识别,就可以说是不具备智能。Google Brain、伯克利以及DeepMind最近在ICLR 2017上获得最佳论文奖项的合作论文就提到,深层网络能够简单记住其训练当中所见到的每一幅图像,这代表着其学习方式与人类仍然存在巨大差异。
然而,目前我们往往很难判断一套神经网络是否已经学会了足以推广到新场景应用的能力。为此,通过逐渐移除越来越大的神经元组,研究人员发现相对于简单记忆以往在训练期间见到过的网络,适应性更强的网络对神经元缺失拥有更好的弹性表现。换句话说,适应性较强的网络更难被破坏(当然,如果神经元移除至一定程度,其仍然会遭到破坏)。

随着越来越多的神经元被移除,具有广泛适应性的网络在效能下降速度方面远低于记忆性网络
通过这种网络稳健性衡量方式,科学家将能够评估是否能够通过为一套网络提供不符合要求的记忆而对其进行"欺骗"。此外,了解网络在记忆过程当中的变化也将有助于我们构建新的网络,从而保证更少地依赖记忆、更多地建立概括能力。
总而言之,这些发现确实能够被用于理解神经网络的力量。通过这些方法,我们发现高选择性神经元在重要性上并不强于非选择性神经元,而适应性更高的网络对单一神经元的依赖性也要低于单纯记忆型网络。这些结果意味着,单一神经元的重要性并不像人们想象中的那么高。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

IIT马德拉斯揭露AI评审员的"视而不见":你的图文AI评判者究竟有多不靠谱?
这项由IIT马德拉斯与BITS Pilani联合发布的研究(arXiv:2604.21523,2026年4月)构建了FOCUS元评估基准,系统检验了评审型视觉语言大模型的可靠性。通过向超过4000个图文和图像样本中注入40种受控错误,研究发现顶尖评审AI的检测失败率在某些条件下超过50%,物理合理性和视觉细节类错误尤为难以被发现,两两比较是最可靠的评审范式。

Sylph.AI提出"最后一个你需要手动搭建的脚手架":让AI自己学会给自己搭脚手架
这篇由Sylph.AI发布的技术报告提出了一套两层自动化框架,核心思想是让AI自动优化自身的运行脚手架,再进一步让AI学会如何更高效地做这种优化。内层的脚手架进化循环通过工人代理、评估代理和进化代理的协作,自动迭代改进单个任务的运行配置;外层的元进化循环则在多个任务上训练,学习一套能快速适应任何新场景的通用进化蓝图,从而彻底消除人工脚手架工程的需求。

英伟达与加州理工学院揭秘:如何让一个毫无经验的AI在虚拟荒岛中自学成才?
这篇由英伟达等顶尖机构联合发表的论文提出了一种名为Voyager的新型智能体。研究团队以《我的世界》为实验平台,通过引入自动课程规划、技能库存储以及迭代反馈机制,成功让大语言模型主导的AI在完全无人类干预的情况下,实现了在复杂开放世界中的自主探索与终身学习。实验数据表明,Voyager在物品收集、探索范围及技能解锁速度上均呈现出远超传统方法的压倒性优势,为未来开发能够自主解决真实物理世界复杂任务的通用人工智能奠定了关键的理论与实践基础。

多所顶尖高校携手攻克AI协作难题:让多个AI像流水线工厂一样不断"迭代进化"
这项由伊利诺伊大学、斯坦福大学、英伟达和麻省理工学院联合发布的研究(arXiv:2604.25917,2026年4月)提出了RecursiveMAS框架,让多个异构AI模型通过轻量级模块RecursiveLink在内部信号层面直接传递"潜在思想",形成循环协作,彻底绕开了传统多AI系统依靠文字传话的低效方式。配合两阶段内外循环训练策略,整个系统只需优化极少量参数,就能在数学、科学、代码生成和搜索问答等9个基准测试上取得平均8.3%的精度提升,同时实现最高2.4倍推理加速和75.6%的token用量削减。

IIT马德拉斯揭露AI评审员的"视而不见":你的图文AI评判者究竟有多不靠谱?

Sylph.AI提出"最后一个你需要手动搭建的脚手架":让AI自己学会给自己搭脚手架

英伟达与加州理工学院揭秘:如何让一个毫无经验的AI在虚拟荒岛中自学成才?

多所顶尖高校携手攻克AI协作难题:让多个AI像流水线工厂一样不断"迭代进化"
