 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
GSMA发布报告 为中国发展eSIM指点方向

能不能用一个手机号码来管理更多的终端,这可能是困扰很多用户的问题。苹果公司在2011年申请的一项虚拟SIM卡专利为这个问题的解决开了个头,2014年苹果公司在推出iPad Air 2时首次将eSIM卡的概念带到实际产品中。不过,对于这一技术的应用却并不一定完全取决于市场的需求,近日GSMA移动智库专门针对中国市场发布的了一份报告――中国eSIM:未来之路。
GSMA移动智库报告从消费电子产品(可穿戴设备、平板电脑和笔记本电脑)、智能手机和物联网三个方面展望了全球eSIM的未来前景,在对中国生态系统内的19家企业进行调研后,从技术、产业合作、商用产品和监管等几个方面审视了eSIM生态系统在中国市场的当前和未来发展。
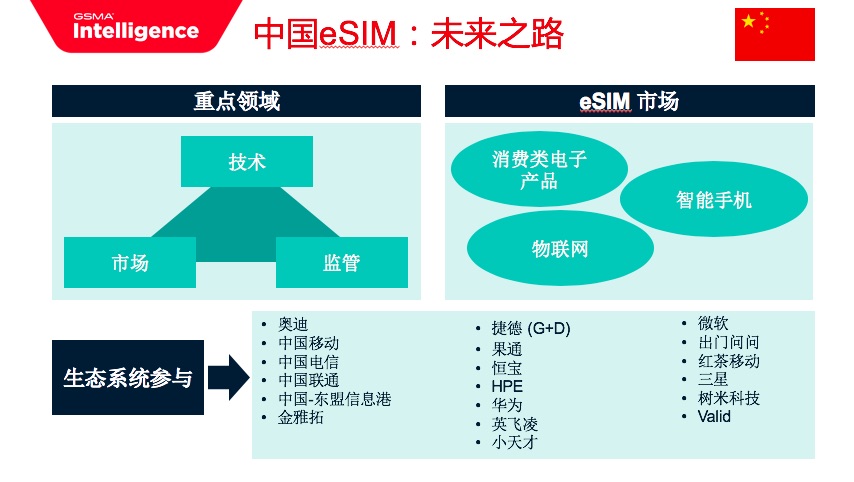
结论显示:在中国,电子消费品(特别是智能手表)和物联网方面的eSIM进展最为明显,中国可能是未来全球最大的eSIM市场,汽车,物流和能源与公用事业是eSIM的三大市场。即便如此,物联网市场仍旧面临碎片化、多样化,安全性以及商业模式不确定的挑战。
但eSIM卡在智能手机的应用上,中国明显落后于全球市场,不仅智能手机中的eSIM尚未推出,而且推出时间表尚不清楚。然而,针对生态系统的调研显示,智能手机是推动eSIM规模和降低成本的关键,同时不可否认的是中国在推动eSIM全球发展方面发挥着关键作用。
eSIM和传统SIM卡的功能一样,其可以通过封装技术固化在终端设备中,而不是作为独立的可移除零部件加入设备中,用户无需插入物理SIM卡。eSIM与SIM卡不同的是,它可以通过OTA空中写卡的方式对卡内数据进行更改,实现远程更新。但这项业务尚未在中国运营商市场予以推行。
通过对19家企业的调研显示,政策和监管为eSIM业务的推广带来了很大压力。因此,他们建议精简监管规则、制定消费者和工业设备的 eSIM 要求、明确证书管理、根证书核发,同时,安全性和跨境互联互通的统一规则对推动eSIM的发展至关重要。

中国联通是最早试水eSIM业务的中国运营商,早在2015年就制定了基于eSIM发展消费物联网业务的战略,打造自主开发的eSIM管理平台;2017年初,eSIM平台开通;2017年4月,eSIM独立号码业务上线。2018年3月7日,中国联通宣布,正式在上海、天津、广州、深圳、郑州、长沙6座城市率先启动“eSIM一号双终端”业务的办理。
2018年5月25日,中移物联正式推出智能物联China Mobile Inside计划,同时发布国内首款eSIM芯片,提供“芯片+eSIM+连接服务”。6月1日,中国移动宣布“一号双终端”业务在天津、上海、南京、杭州、广州、深圳、成都7个城市正式启动。用户通过一号双终端业务,可实现手机与可穿戴设备的绑定,共享同一个号码、话费及流量套餐。
中国电信去年11月初宣布发售经过重新设计的Apple Watch Series 4,内置蜂窝网络,提供突破性的通信、运动和健康功能。此前,中国电信Apple Watch eSIM一号双终端业务已经于10月31日正式开通。
显而易见,三家运营商的eSIM卡业务还只停留在物联网和消费电子层面。如果eSIM卡取代SIM卡,那么手机号码就不再成为运营商和用户之间的紧密纽带。同时,运营商基于SIM的增值业务、收费模式也将面临被颠覆的挑战。然而,eSIM技术应用到蜂窝手持设备中已是大势所趋,GSMA移动智库报告预测,2025年,中国高、中、低端智能手机中采用eSIM技术的比例将达到35%、29%、20%。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
