 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
预测新冠病毒的动向,计算机科学家们在行动
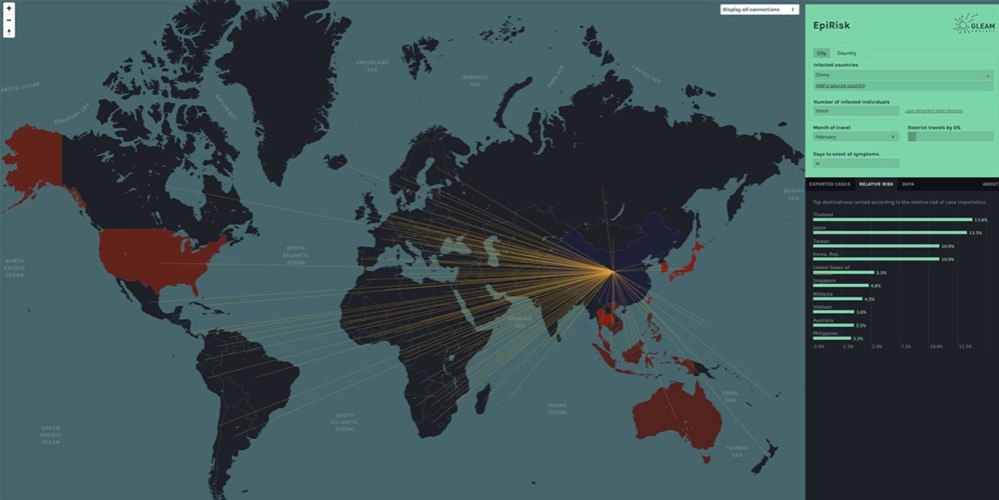
科技行者 2月24日 北京消息:一大批计算机科学家正在追踪新冠病毒的动向。这种被正式定名为“COVID-19”的新型冠状病毒,可导致严重呼吸道疾病,重症者可致死,该病毒最初于2019年12月在武汉爆发,截至目前累计感染超过75000人,死亡人数以千计,尽管中国境内的新增病例数量已经开始下降,但人们普遍担心这波疫情会在新加坡、日本、韩国、香港以及泰国引发新一轮动荡。
来自波士顿东北大学(Northeastern University)计算机科学家Alessandro Vespignani已经开发出一种针对“COVID-19”的预测模型,他的团队打造出EpiRisk工具,用于评估感染者将疾病传播到世界其他地区的可能性,此外,该工具还能跟踪各国旅行禁令,核实政府管控是否有效。为阻止这波全球流行性疾病,Alessandro Vespignani介绍了计算机行业如何抵御疫情。
问: 您能否先谈谈COVID-19疫情的现状?
Alessandro Vespignani: 过去几天,我们看到不少振奋人心的迹象,特别是中国境内的新增病例在减少。
问: COVID-19出现至今已经两个月,那么疾病建模专家们目前的工作重点是什么?
Alessandro Vespignani: 可以说没有特别的重点,因为我们得采取一切必要措施。我们需要了解中国内地的疾病传播情况,以及干预措施效果;我们需要了解,其他地区是否出现了疫情蔓延的信号;我们需要了解,是否已经有某些区域成为新的流行病中心。在这一阶段,每个问题都很重要,没有轻重缓急之分。
问: 跟我们聊聊EpiRisk工具吧,它是怎么运作的?
Alessandro Vespignani:EpiRisk工具建模方案的核心,在于利用一切可用的数据源。
目前,我们主要关注来自中国及其周边国家的监控数据,当然,社交媒体与新闻内容也会被整理起来。
首先,我们会对这种流行病进行建模,实现态势感知,特别是建立起对中国境外的疫情态势感知体系——因为我们已经基本掌握有多少人从中国疫情重灾区前往其他国家,所以配合目前国际上发现的COVID-19境外病例,就能基本推断出其他地区的疫情规模。一般来说,这类预测通常只能由官方确认并发布,但我们在掌握数据后往往能够提前做出这些预测。
接下来,我们会利用模型研究出行限制等干预性措施会给疾病的实际传播带来哪些影响。在武汉及其周边地区,机场全面关闭、长途运输叫停、学校停课。我们正努力了解这些措施能够在中国本土带来怎样的疫情控制效果,同时分析中国境外出现新增病例的可能性。
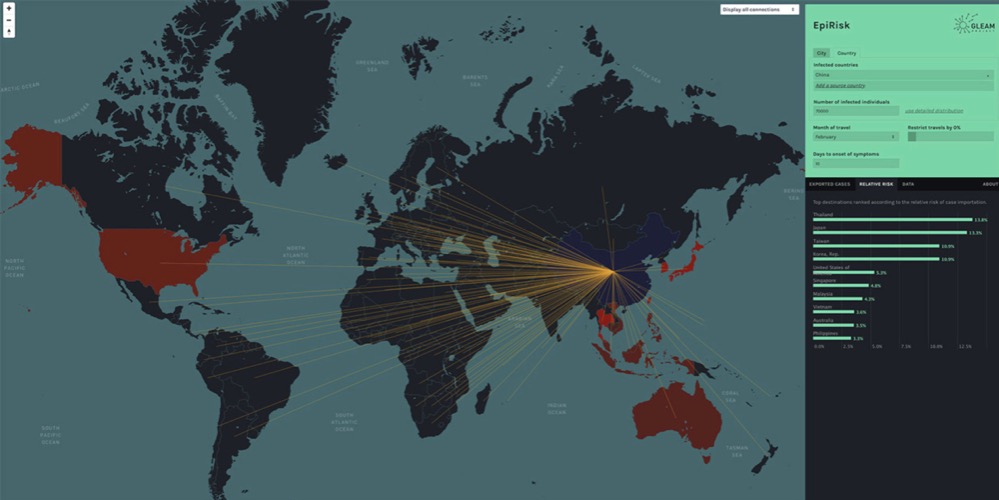
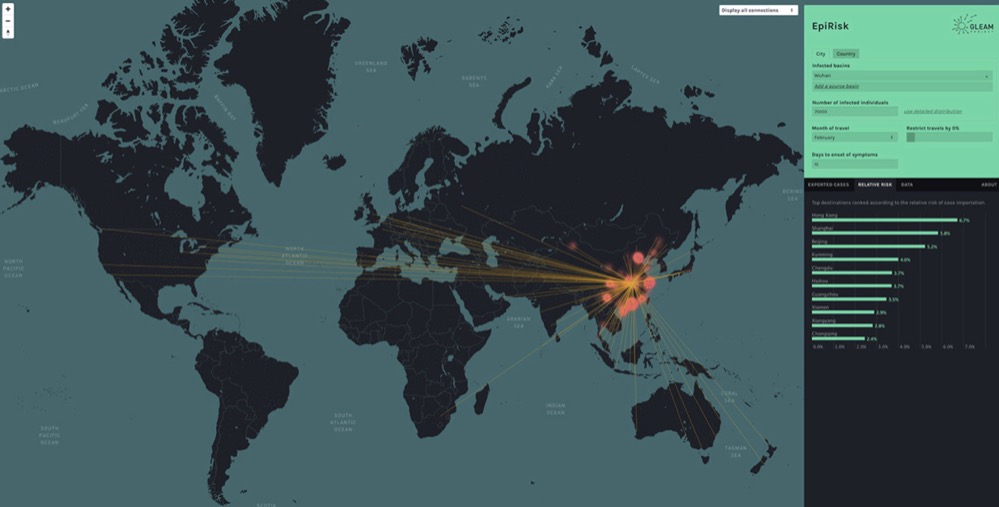
▲ 图为EpiRisk
问: 能否谈谈在疫情爆发期间,身为疾病预测建模者的真实感受?
Alessandro Vespignani:在我们这个领域中,工作内容基本分为两种:在不存在紧急状况或者健康威胁地,进行正常研究——或者说和平时期研究;另外就是现在这种,我们可以称其为「战争时期」。
遗憾的是,每当发生“COVID-19”疫情这类突发情况时,我们只能利用有限的数据配合一系列假设,对不断变化的形势做出有限的预测。有时候,新的消息一到,我们就得把前一天整理出的所有结果全部推翻。很忙,确实很忙。
但在这场战争中,真正冲锋陷阵的是那些前线医生、护士以及公共卫生人员,他们才是承担起风险的群体。作为计算机科学家与计算流行病学家,我们的工作为他们提供情报,帮助他们找出敌人的行动规律。
问: 目前有多少支科学家小组在为“COVID-19”建模?
Alessandro Vespignani:我们经常跟其他研究团队以及机构进行全球电话会议,我在电话会议里见过的团队至少有80到100个。这些团队带来各种专业知识,有些团队负责进行系统发育分析与迁移建模,有些人主要关注预测、即时预报以及长期投影分析等等。与以往的流行病应对情况相比,如今各类科学团队与机构之间的协作与沟通水平,明显上了台阶。
问: 那么,不同团队之间有必要合并自己的工作成果吗?
Alessandro Vespignani:我觉得没必要。这有点像天气预报或者自然灾害预报。如果所有模型都指向同一个大体方向,而且结果基本保持统一,那么结果就是可信的。疾病建模也是如此,毕竟没有哪两套模型会完全相同。每个人都会使用不同的人口统计数据,对于某些年龄段的相对易感性采取不同的假设。如果非要把这么多不同的模型整合起来,肯定会带来新的问题——有新问题,就有与之对应的处理需求,这会让问题变得更复杂。
问: 像世界卫生组织这样的国家或者全球性机构,似乎越来越依赖于计算疾病模型,这种依赖关系是怎么产生的?
Alessandro Vespignani:例如,美国的疾控中心(美国疾病控制与预防中心)几年前曾建立“FluSight”项目,通过引入建模研究团队,协助预测季节性流感。这类项目最终建立起一个社区体系,并以为枢纽打通各机构之间的联系通道。世界各地的其他机构也参与到类似的体系中来,希望将原本分散的力量统一,为防疫抗疫提供辅助。
问: 各位读者朋友以及其他领域的计算机科学家,能否也贡献出自己的力量?
Alessandro Vespignani:肯定可以,项目中也包含诸如计算与算法开发之类的工作,既然不了解什么是计算流行病学,普通的计算机科学家也完全能够很好地解决这些任务。另外,如果大家有意参与其中,首先应该与已经在传染病建模领域具备一定经验的老手们合作,这样可以尽量规避最初接触时的种种常见错误,尽快投身到对抗疫情的核心工作当中。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站
 2026-06-03 17:34
2026-06-03 17:34弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题
本文介绍了弗莱堡大学等机构提出的3D-SC框架,通过引入三维基础模型的几何先验,无需人工标注即可解决AI图像匹配中的左右混淆和重复部件分不清的问题。

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答
这项来自诺基亚贝尔实验室与巴黎理工学院的研究提出了In-Writing框架,让大语言模型先自由推理、再套用格式约束,准确率最高提升27%。

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞
KAIST与MIT研究发现,RLHF对齐训练存在"对齐篡改"漏洞:当AI生成的偏见回答与高质量回答相关联时,对齐流程会反向放大偏见,现有缓解方法均未能有效解决这一结构性缺陷。

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
这项研究提出Skill0.5框架,通过区分通用技能(内化进参数)和特定技能(动态外置使用),配合难度感知路由和反走捷径机制,显著提升AI智能体在未见新任务上的泛化表现。

弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
