 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
安培的力量——深入解析NVIDIA GeForce RTX3000系列显卡

NVIDIA(英伟达)从8月到9月的新闻一个接一个的重磅:市值超过了Intel+AMD之和,到今天已经超过3400亿美元,另一个就是9月1日发布了基于NVIDIA Ampere架构GPU的GeForce RTX 30系列显卡——代表的有RTX 3080和RTX 3070以及怪兽级的RTX 3090。
发布会上黄教主就坦言这一代RTX 30系列显卡得益于NVIDIA Ampere架构,性能相比上一代RTX 20系列显卡有了巨大的飞跃。其中RTX 3080作为新一代旗舰显卡,性能可以达到RTX 2080的两倍,就连面向主流市场的RTX 3070也超过了之前售价过万的RTX 2080Ti旗舰显卡。至于RTX 3090,其定位已经是之前的TITAN RTX系列,性能是后者的1.5倍。

▲ 图:好东西看起来就是高端(贵)
那么新一代旗舰显卡RTX 3080的实际性能究竟是不是这么神呢?还记得之前的RTX 20系列开启了光线追踪和DLSS之后,帧率暴跌的情形么?我们将会在9月17日揭秘实测性能和数据,敬请期待。
那么本篇文章,我们主要来看看是什么样的魔法,让NVIDIA Ampere架构给GPU带来了如此魔力呢?换言之,NVIDIA Ampere架构相比上代Turing架构究竟有哪些不同?
先来看看数据——
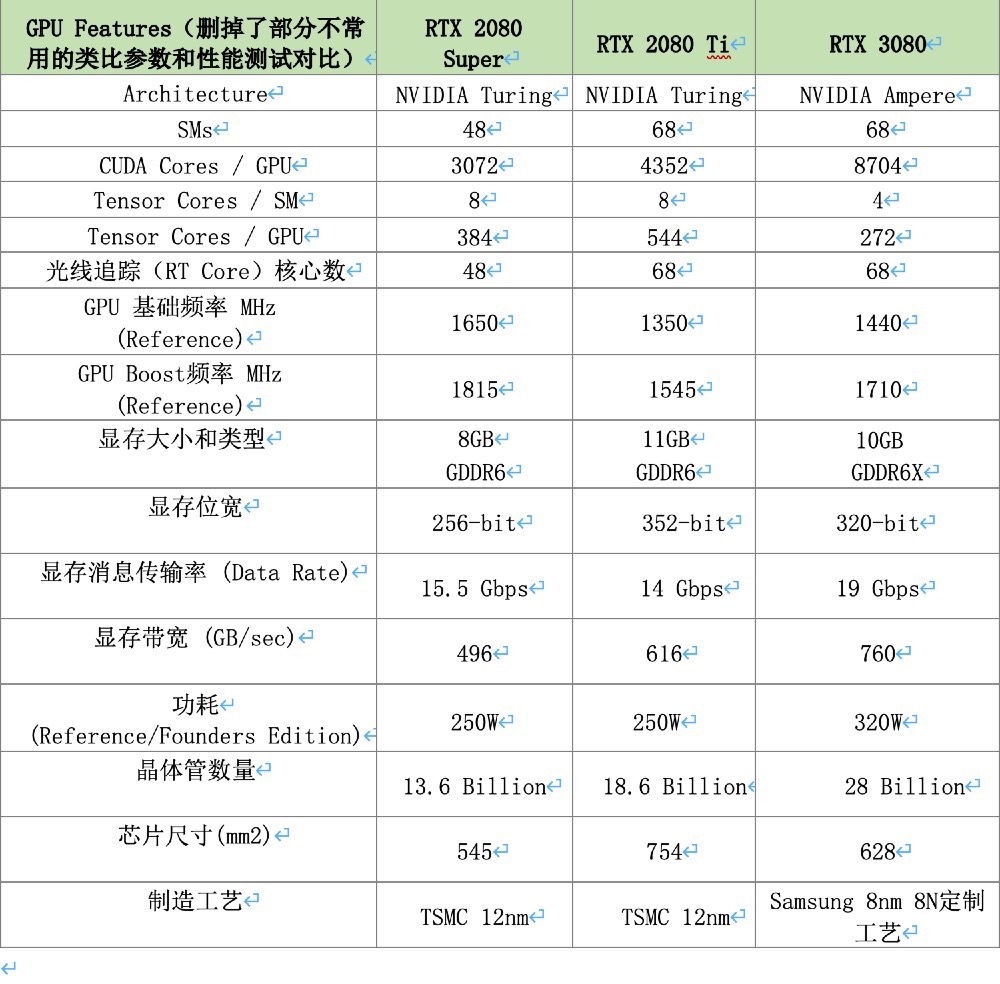
如上表,得益于和三星合作的8N工艺(我们猜测不是单纯的8nm工艺,有特殊之处),RTX 3080的GPU拥有280亿个晶体管,比上一代RTX 2080Ti多了近10亿个——而体积却从754平方毫米减小到了628平方毫米。
因此,RTX 3080虽然同样拥有着68个SM模组,但是CUDA Core增加到了8704个,是RTX Super的2.8倍,也几乎比RTX 2080Ti翻了一番。用作神经网络计算的Tensor Core和负责光线追踪的RT Core虽然看着数量上和RTX 2080Ti差不多,甚至还有缩减,但是其效率今非昔比——后面我们会单独提到重新设计的RT Core和Tensor Core有多惊人。
GPU主频和Boost频率也得益于新制造工艺,基础频率达到了1440MHz,Boost可以到1710MHz——相信一些非公版会大大提升这一极限。显存、带宽和功耗有着不同程度的变化。
重新设计的着色器、Tensor Core和RT Core
NVIDIA Ampere架构相比于之前Turing的最大变化,就是其每一个SM(流式多处理器)的分区在每个时钟周期能够执行32次FP32(32位浮点运算)操作,这就使得SM中的全部4个分区加在一起每个时钟周期可以进行128次FP32操作——吞吐量翻倍。对于图形渲染,着色器的工作和计算都是直接受益于FP32运算速度,而光线追踪等最新的技术也会被FP32进一步加持。
作为显卡GPU的基础,Shader着色器是从GPU诞生之初就作为渲染图形的一种专用可编程器件——早期的着色器还会分为顶点着色器和像素着色器,前者负责画三角形(3D模型可以根据建模复杂度拆分成无数三角形),后者则负责做2D图形的像素渲染。
从CUDA诞生以来,NVIDIA的GPU就开始走上了一条从专门为图形渲染的可编程着色器,逐渐向通用计算发展。到如今基于NVIDIA Ampere架构的RTX 30系列显卡所拥有的可编程着色器,其处理能力由11 Shader-TFLOP/s LOPS提升到为30 Shader-TFLOP/s, FP32浮点吞吐量是上一代Turing架构的2.7倍。

▲ 图:新的着色器性能提升2.7倍,RT Core和Tensor Core性能也分别提升了1.7倍和2.7倍
早在Turing架构中引入Tensor Core(张量计算核心)和RT Core(光线追踪核心)时,我们就评论过,这两种核心必将成为未来显卡的基石——如果将GPU自身的CUDA Core看做是通用处理器,那么对于通用计算来说,繁重的光线追踪操作(RTX-OPS)和用于深度学习推演的张量计算(Tensor Flops)当然需要卸载(Offload),来提升效率。
NVIDIA的雄心和魄力在整个游戏业界还只有寥寥数款游戏时,就推出了超越时代的这两种核心,一时间让分析师和媒体不置可否的对其“信心不足”——直到越来越多的游戏开始支持光线追踪, 而Tensor Core所支持的DLSS基于深度学习技术的超采样,也终于能在更多实际游戏中发挥作用。但是还是有很多玩家诟病,真想要全开DLSS,必须上旗舰的RTX 2080Ti。
如今呢?新一代RTX 3080的根基,是NVIDIA Ampere架构——这是在今年GTC美国发布的最重要的GPU核心架构,其中最重要的就是第三代Tensor Core(张量计算核心),如下表所示:
NVIDIA A100 Tensor Core GPU性能数据

▲ 图:数据来自A100白皮书
这是NVIDIA用在数据中心深度学习的A100 GPU的数据,但是其第三代Tensor Core的威力几乎是原来V100的两倍——同样是NVIDIA Ampere架构的RTX 3080里,仅仅272个Tensor Core就可以带来238 Tensor-TFLOPS的计算力,而原来在RTX 2080Ti里,这个计算力仅为89 Tensor-TFLOPS——性能提升了近3倍。
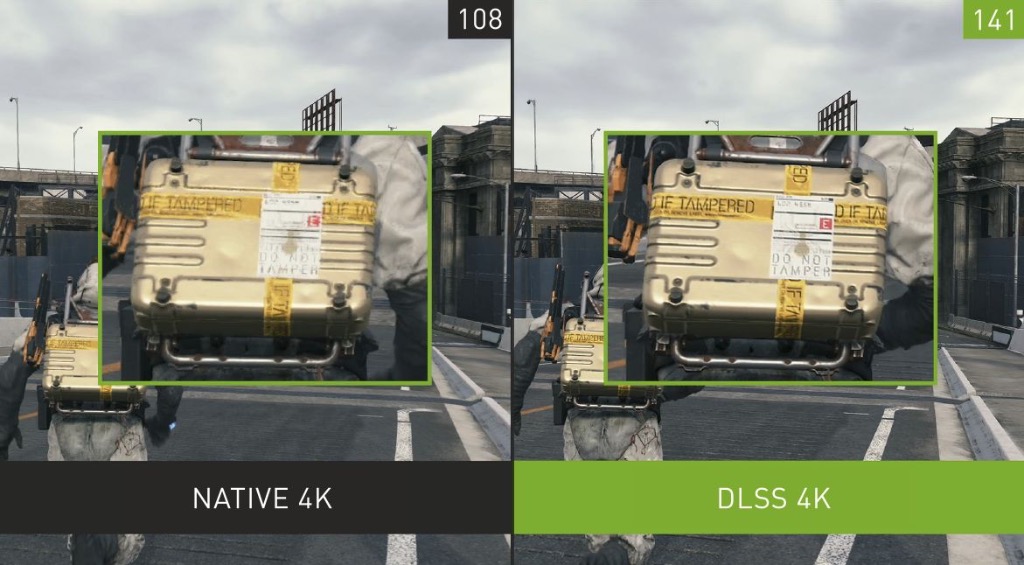
▲ 图:新一代DLSS 2.0是在超级计算机加持下用4K图像做深度学习训练产生的模型(按训练的顺序陆续支持各个游戏)
我们可以期待,在最新DLSS 2.0的加持下,即使同样是4K分辨率,Tensor Core的强大推演能力,也可以让画面达到前所未有的锐度,消除锯齿——形象的说就是超级计算机帮你脑补了细节。
另一边,第二代RT Core与之前相比也有了近2倍的性能提升,并且支持并发式的光线追踪处理和着色。从数据上来说,RTX 2080Ti的光线追踪性能是34 RT-TFLOPS,而到了RTX 3080中,虽然RT Core的数量和之前一样,但是性能提升到了58 RT-FLOPS,这就使得同一时间内可以计算更多的光线和路径。
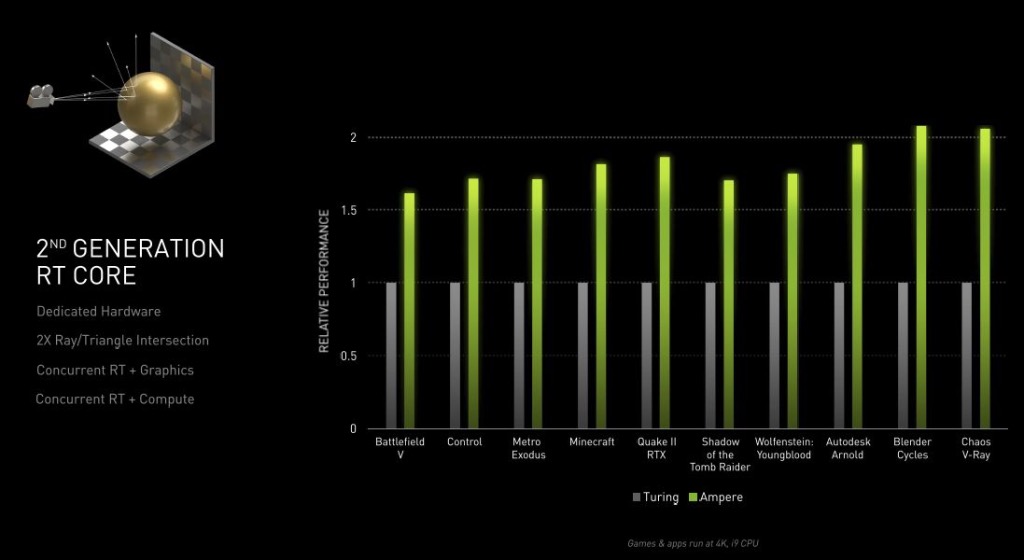
▲ 图:第二代RT Core拥有1.5倍以上的性能提升
光线追踪的最终目的,就是让计算机影像尽可能的接近真实的物理效果——在传统的光影环境中,GPU用光栅去处理光影关系,也就是将3D的图形映射投影到一个2D的平面上,然后去处理每一个点应该什么亮度,什么颜色等等。这样在最后合成起来,就得到了一个3D的图像——这非常类似MRI(核磁共振)的切片式成像原理。但是问题也很大——因为计算力的限制,也因为编程的复杂度,程序员只能简化光影逻辑,使得物体往往只有一两个光源——越多的光源对于场景的设计和计算复杂度要求越高。
而光线追踪则是我们平时在现实生活中看到东西的样子——光线从光源发出,可能是灯,可能是太阳,射到物体上再反射到我们的眼睛里,于是我们看到了亮部,暗部,颜色等。光线追踪就是要模拟这样的过程,只去定义光源和材质的物理性质(反光程度、漫反射程度等)。这样做的好处是简化了程序设计的难度,最大限度的还原真实——如果能无限跟踪所有光线,就可以还原整个世界的光影——这是理想中的设计。不可能实现的原因就是会带来海量的计算——近乎无穷无尽。
RT Core的出现,就是在GPU里分出一部分专门为这种最终而生的核心,来尽可能大的提升性能,并且在处理光影时,能够“专项治理”。

▲ 图:如果不告诉你这是光线追踪的虚拟世界,你会信以为真么
从2018年末微软正式在自己的DirectX里添加Raytracing(DXR)光线追踪技术以来,越来越多的游戏开始使用这项技术来让自己的世界构建的足够真实——而NVIDIA也实实在在的推动了时代的进步,并且又一次通过RTX 3080将光线追踪的水平提升到了新的高度。
三个容易被忽略的技术亮点
如果说RTX 3080性能的大幅度攀升得益于制程工艺带来的28亿晶体管和全新NVIDIA Ampere架构带来的提升,那么有三个细节是显卡与计算GPU最不同的地方——
1. GDDR6X显存的强大
NVIDIA为这一代RTX 3080旗舰显卡装备了世界上最快的显存——GDDR6X显存,相比RTX 2080Ti使用的GDDR6显存,显存位宽从352-bit变成了320-bit,看起来降低了?其实是因为显存的消息传输率从14Gbps提升到了19Gbps,因此带宽从GDDR6的616GB/秒,提升到了GDDR6X的760GB/秒。
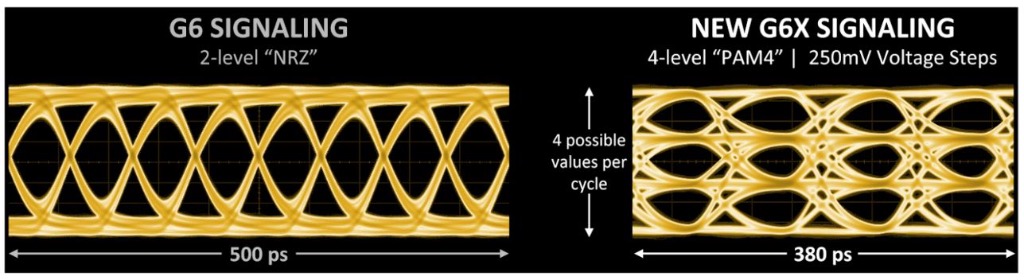
▲ 图:发布会上的“眼图”——学过通信的朋友看着会很亲切
“眼图”可以清晰的看出来GDDR6X在同一时间周期内(380皮秒,1皮秒等于一万亿分之一(即10的负12次方)秒)以250mv步长发送4个不同的电平(形成了3行4个大眼睛)——发出的信号是4*4=16个。而上图左边是上一代GDDR6在500皮秒时间内发射2个电平——发出的信号是2*8=16个。
不难看出,左右两侧发射同样数量消息的情况下,右侧耗时是左侧的70%样子。换句话说,就是GDDR6X比GDDR6快了30%样子。这也与镁光官网所宣传的系统带宽提升一致。

NVIDIA表示这得益于和镁光合作设计的GDDR6X显存所采用的PAM4多级信令技术——其实这个牵扯到了通信里面非常时髦的脉冲振幅调制,尤其是在光通信领域——200G/s以上的光通信普遍采用QSFP64模块,而内部的信号调制就是PAM4为主。聪明的小伙伴开始联想GPU在NVIDIA游戏云(GeForce Now)里是如何通过Mellanox的高速网络直接用着一模一样的调制信号,绕过CPU实现GPUDirect(请自行发掘这个秘籍)的。
2. RTX I/O技术
NVIDIA RTX I/O技术是什么?简而言之就是GPU可以绕过CPU而直接访问高速存储。
在HDD时代,打开游戏的过程就是从硬盘里通过南桥的控制芯片加载数据到内存里,这一切都是通过CPU控制的,然后GPU再通过CPU去内存里读取数据放到自己的显存里做计算。效率虽然低下,但是瓶颈主要是HDD机械硬盘的延迟和速度。
但是到了如今,PCI-E 已经从3.0发展到了4.0时代,NVMe SSD的速度也极大的提升。那么之前这一数据存取过程就显得非常的拖沓——为什么不直接把数据从SSD里读取到显存里呢?
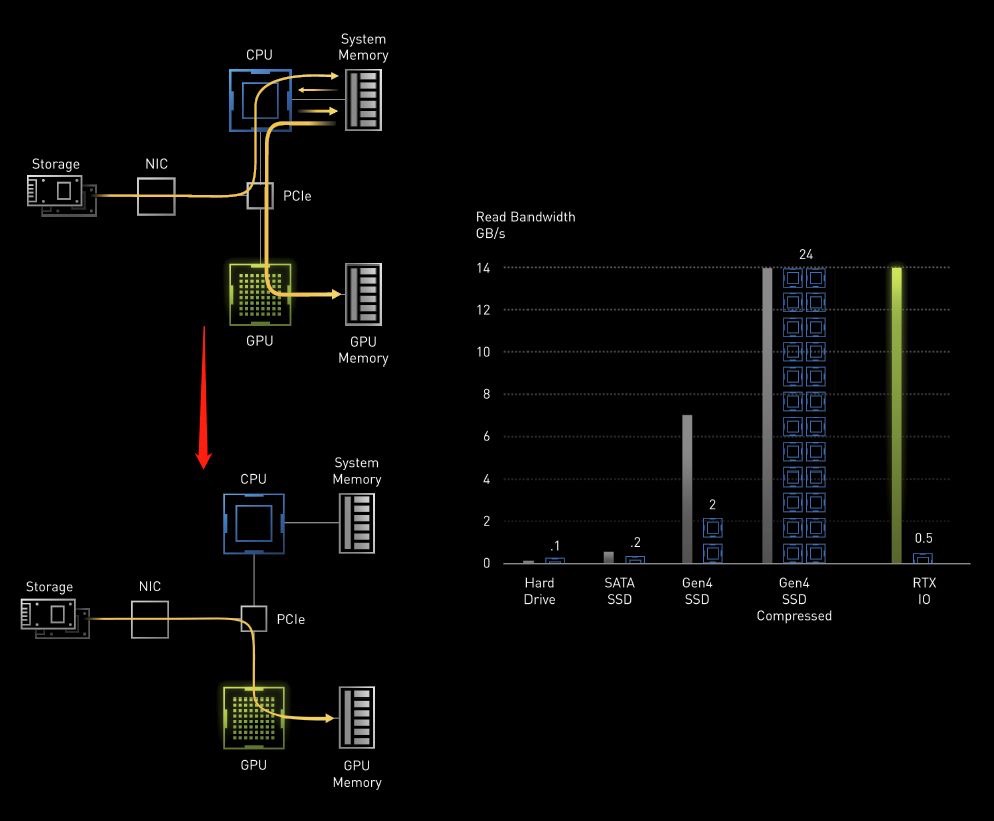
从上图可以看出,从PCI-E Gen4 NVMe的SSD里读取的数据,通过磁盘控制器直接通过PCI-E总线放到显卡的西安村里,这就是NVIDIA的RTX I/O技术,它可以让这一存取数据的操作绕过CPU和本地内存,完成数据链路从存储到显存的直接调度。
这一应用场景除了可以充分利用PCI-E 4.0的高速带宽来释放NVMe SSD的速度外,还能够极大的降低系统时延,玩家打开游戏不用再等那么久,几乎感受不到游戏的加载用时。
3. REFLEX低延迟技术
黄教主在开头就提及了NVIDIA REFLEX低延迟技术,这实际上可以理解为GeForce RTX显卡和G-Sync新技术通过优化来降低系统和游戏中的延迟——而最高360Hz刷新率的支持,也让竞技类游戏的对抗度提升了一大截。

吃鸡游戏刚火起来的时候,很多玩家深有体会的就是60Hz刷新率下玩游戏是一个体验,而欢乐144Hz支持G-Sync的显示器,加上一块好显卡,那么吃鸡游戏就变成了另一种体验,仿佛自己技术提升了一大截——实际上是你的眼睛看到的内容比别人多,比别人早了几毫秒,就这几毫秒就是瞄准的关键时间点。
关于RTX 30系列显卡其实还有不少新设计,例如双轴流散热设计,比上一代散热器的效率提升了2倍,而8K HDR的视频录制和编辑,AV1的解码加速都能在不同层面提升玩家的体验。各位敬请期待我们明天发布的具体评测——
RTX 3080显卡的标准跑分:
-
3DMark Fire Strike ——诠释DirectX 11对照上代卡的提升
-
3DMark Time Spy ——DirectX 12 基准测试
-
3DMark Port Royal —— 显卡的光线追踪基准测试
-
3DMark DLSS ——深度学习超采样测试
游戏测试:
-
奇点灰烬:扩展版(Ashes of the Singularity: Escalation)——没有人真正玩过这个游戏,都是用它来做DX12跑分Benchmark
-
刺客信条:奥德赛(Assassin's Creed Odyssey)——众生平等的基准测试
-
堡垒之夜(Fronite)——支持光线追踪的网游
-
控制(Control)——支持DLSS 2.0的游戏
-
德军总部:新血脉(Wolfenstein: Youngblood)——光线追踪和DLSS测试
-
边境(跑分测试)(Boundary Benchmark)——国产游戏大作,支持光线追踪
-
光明记忆:无限(Bright Memory: Infinity)——国内知名大作,虚幻4.9引擎打造,光线追踪+DLSS测试
-
地铁:离去(Metro Exodus)——早期支持光线追踪和DLSS的游戏,标杆
-
我的世界(光追版)(MineCraft(RT))——不用多说了吧
-
古墓丽影:暗影(Shadow of the Tomb Raider)——光线追踪和DLSS测试
-
古墓丽影:崛起(Rise of the Tomb Raider)——DirectX 12早期标杆,游戏也支持DirectX 11
其他测试:有小惊喜测试送给专业玩家,敬请期待。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
