 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
全球冠军!紫光展锐多媒体算法斩获MOT20榜单第一
上海,中国 – 2021年1月19日- 在国际权威的多目标跟踪挑战(Multiple Object Tracking Challenge,MOT)MOT20榜单上,紫光展锐多媒体算法的mota指标超过70分,拿下全球冠军。这也是MOT20 Challenge榜单上唯一一家超过70分的企业,彰显了紫光展锐在多目标跟踪领域的业界领先水平。
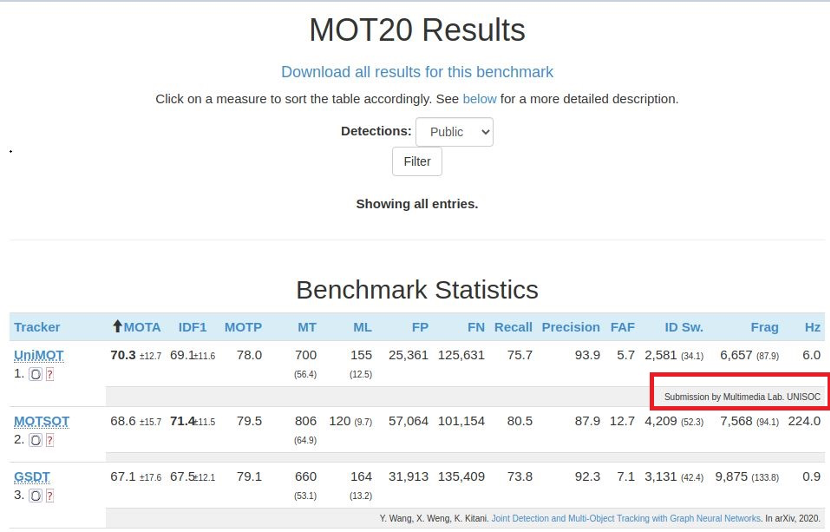
MOT Challenge是多目标跟踪领域最权威的国际测评平台,由慕尼黑工业大学、阿德莱德大学、苏黎世联邦理工学院以及达姆施塔特工业大学联合创办。MOT Challenge 提供了非常准确的标注数据和全面的评估指标,用以评估跟踪算法、行人检测器的性能。

其中,MOT 20 benchmark包含8份新的视频序列、密集且极具挑战性的场景。这份数据集在4th BMTT MOT Challenge Workshop,CVPR 2019上首次发布,平均每帧高达246个行人,相比之前的挑战赛数据集增加了夜晚数据集,对现有SOTA的MOT算法在解决极端稠密场景、算法泛化性等方面提出了艰巨挑战。
紫光展锐在多媒体算法中针对网络结构设计、损失函数、训练数据处理等方面进行了大量的创新和探索。针对竞赛中训练集没有涉及到的场景,紫光展锐创新性的采用端到端同时检测、行人识别策略,保障了算法在实际落地时的实时性,同时针对不同的端侧算力灵活调整网络大小,可灵活配套多种芯片方案的部署。
同时参与本次竞赛的还包括牛津大学、卡耐基梅隆大学、清华大学、慕尼黑工业大学、中科院、微软等多家企业、大学和科研机构的相关团队。
多目标追踪技术作为承载监控、车载、无人机、赛事直播等应用的关键技术,可准确捕捉视频中的关键信息,为进一步的信息提取提供支持,将在智慧城市、物联网等领域得到越来越广泛的应用。
在智能监控场景中,算法可实现复杂场景下的目标自动提取、跟踪、识别,理解目标的活动状态,进而实现场景状态监测、识别等。多目标追踪技术的应用可大幅减少人工重复劳动、提高工作效率和监控系统的智能性、安全性;在赛事直播场景中,算法可自动提取运动员的运动状态,从而实现数据统计、自动导播等功能,挖掘更多的数据价值;在智能车载场景中,算法可获取道路中车辆、行人的运动信息,为自动驾驶、安全辅助等应用提供必要的决策数据支持。
图像算法正在深度融合到越来越多的垂直行业,形成乘法效应,衍生出创新的业务和应用,让人们的生活更加美好和便捷。
MOT challenge榜单官网:https://motchallenge.net/results/MOT20/?det=All


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
