 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
阿里云贾扬清:大数据+AI工程化 数据真正变成资产

5月20日,阿里巴巴副总裁、阿里云计算平台负责人贾扬清在媒体沟通会上表示,数字经济迅猛发展,不断丰富、增长的数智业务,对技术提出了更高的挑战,企业的数字化创新需要用好“大数据+AI”这个“核武器”。
经过近20年的发展,大数据已从早期的数据挖掘进化为承载数据分析、数据管理、数据协同的综合治理平台。阿里巴巴在数据治理方面拥有丰富的经验,无论是简单、易用、弹性的云数据仓库MaxCompute,还是提供一站式数据开发、管理、治理的平台DataWorks,都能成为企业数字化的“好帮手”。
建筑行业领头羊——中建三局一公司,就基于阿里云的DataWorks和MaxCompute构建了数智建造一站式服务平台。该平台覆盖了建造领域生产场景全链路、核心管控全流程和智能决策全视角,使建造类企业实时感知、动态控制和智能化决策成为现实。
中建三局只是建筑行业的一个缩影。事实上,大数据技术早已经广泛应用到各行各业的数字化转型中。
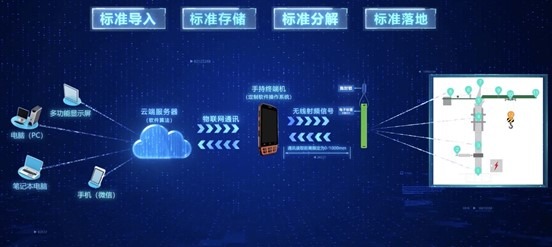
中建三局数智建造一站式服务平台
金融行业,天弘基金每天有百亿级数据量实时在线交易,采用阿里云飞天大数据平台,使数据清算时长从8小时缩至1.5小时;在线教育行业,VIPKID在阿里云大数据技术的辅助下,实现了60%的问题自动化处理,投诉率降低66%;快狗打车基于阿里云,实现了经纬度数据实时决策,15秒及时响应,3分钟车到位,货车空驶率降低30%……
对企业来说,业务要创新提高效率,仅仅把数据管的好、用的好,还不够,还需要AI技术的加持。“大数据和AI密不可分,结合在一起,更能帮助企业在数字时代从容应对不确定性。”贾扬清表示。
随着数据量越来越大,模型变得越来越精准、高效且复杂。因此,无论是在数据还是计算方面,都需要有一个更加大规模、大体量的底座,来支撑上层AI的需求。
为此,阿里云机器学习平台PAI构建了灵活、易用和功能丰富的机器学习全栈产品:PAI-Studio(可视化建模平台)、PAI-DSW(云原生交互式建模平台)、PAI-DLC(云原生AI基础平台)、PAI-EAS(云原生弹性推理服务平台)。
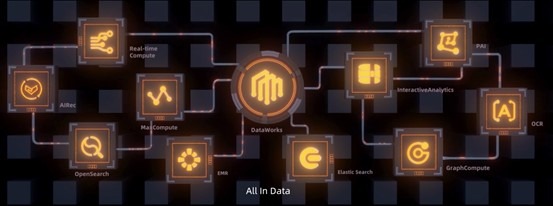
对企业来说,工程化已经超越算法,成为AI落地的更大瓶颈。日前,阿里巴巴与清华大学合作发布了超大规模中文多模态预训练千亿参数模型M6。该模型的数据集包含超过1.9 TB图像和292GB文本,参数规模达到1000亿,可完成产品描述生成、视觉问答、问答、中国诗歌生成等跨模态任务。
目前,M6已经用于业务场景里。在犀牛新制造的服装设计上,M6可以根据潮流趋势文本的描述,自动产出细节清晰的服装图,并符合生产标准。

我们希望将M6的场景化服务能力开放给所有企业。”贾扬清表示。
要把AI转化为生产力,不仅要懂 AI、还更要懂行业。阿里云机器学习平台PAI以电商、金融、游戏、直播等业务为起点,在智能推荐、用户增长、金融风控、音视频文本等多模态场景积累了丰富的实战经验,沉淀了大量成熟算法、框架及工程化组件等“原子能力”,帮助开发者及企业客户更快地孵化和构建新场景业务。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
