 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
展锐第二代5G芯片平台实现量产 CEO称“明年芯片将不再供应短缺”
12月27日,紫光展锐CEO楚庆通过线上发布会官宣,公司的第二代5G芯片平台实现客户产品量产——这是公司首款6nm 5G芯片,支持5G Rel-16标准,意味着公司已具备先进制程芯片的研发与商用能力。
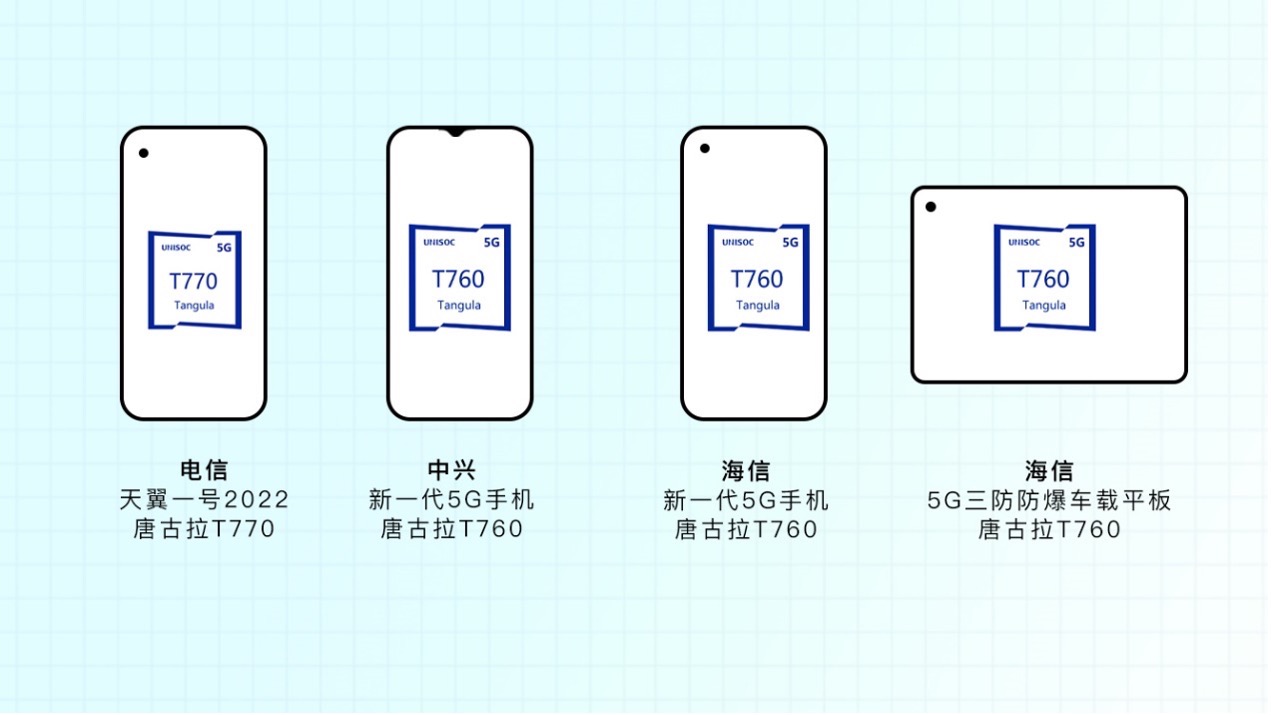
当下,展锐正在全力冲击5G芯片,过去两年内发布了两代5G芯片,第二代包括两款产品:唐古拉T770、唐古拉T760。目前,T770搭载在中国电信的新一代云手机天翼1号上,T760搭载在中兴和海信的新一代5G手机上,其中中国电信和中兴的手机将于2022年上市,另外T760芯片还搭载在海信的一款5G车载平板上。

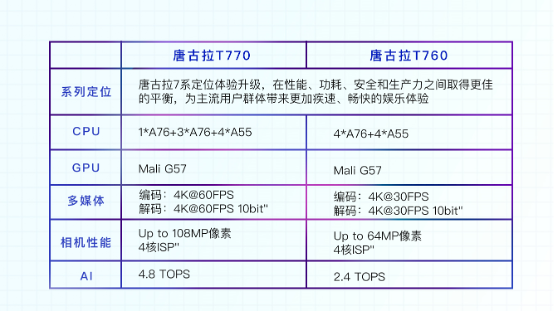
据官方介绍,相比第一代,第二代芯片在性能上最高提升100%以上,在集成度上提升超过100%,在性能、功耗、安全、生产力之间也取得最佳的平衡。实现客户产品量产,意味着芯片平台的产品成熟度和质量都已达到了能够直接面向消费者等最终用户的状态,只有实现客户产品量产,才真正代表芯片平台完全达到了设计目标。
紫光展锐的5G芯片在第一代产品上采用12nm工艺,第二代采用6nm工艺,两种工艺都属于先进工艺范畴。楚庆表示,后者的经济投入要比前者大5倍以上,越往下一代工艺,投入就越大,从6nm到5nm的经济投入会提升2.5至3倍。
5G手机的基带芯片,一直是芯片技术最为复杂的领域之一。作为一种让全球各个区域都能使用的通用芯片,要支持不同国家地区的不同频段,这使得芯片设计极为复杂,仅仅是对2G、3G、4G兼容这一项要求,就足以让大多数厂商望而却步。研发5G,考验着公司团队的前期研发、技术储备、资金实力,投入巨大。
楚庆坦言,5G芯片研发难度很大,因为那是一整套方案,且“覆盖了人类有关芯片知识的全版图”。展锐第二代5G芯片平台拥有完整的5G主平台套片+可选配的5G射频前端套片等多达十多颗芯片。其中5G主平台套片包含主芯片、Transceiver、电源管理芯片以及connectivity芯片等7颗芯片;5G射频前端套片包含PA等多颗芯片。

楚庆称,客户现在也要求紫光展锐提高到先进厂商的行列,“后面的竞争只会是越来越激烈,所以在每一款芯片上,公司都是在赌命,如果赌输了的话,后果可能是倒闭”。同时,展锐也在进行治理架构的调整,这也是一项巨大挑战和不确定因素。
对于产业未来,楚庆表示乐观。“2022年,按我的判断,会发生一个逆转。”楚庆说道,芯片经历了近一年的供应短缺之后,到明年第三季度,将从供应短缺阶段进入到供应充足阶段、再到供过于求的阶段。“在供过于求的局面里,大家都可以获得丰富的产业资源,如果这个时候不能利用好这些机会给自己填满燃料、全速前进,别人将超过你,你将失去机会。”
他认为,无论是处于紧缺时代,还是供应充足的时代,对于5G玩家而言,都有不同的赛道,但最终竞争结果是一样的,就是优胜劣汰。
楚庆还称,当前中国的5G发展带来了巨大机遇。他表示,只有东亚还在正常且迅速地推进5G,其中主要是东亚三国——中国、日本和韩国,尤以中国为甚。“现在中国的六百多个地级市都被5G覆盖了。”他认为,“如果你是一商人,必须发现这一点。而且,一定要有实际行动,与其临渊羡鱼,不如退而结网,赶紧做好发掘未来金矿的准备,否则会错过这辈子最好的机遇。”
尤其是今年才封板公布的5G Rel-16标准,它才是真正释放5G全部潜力的标准。“我们有关它是如何改造人类社会的,如何改造工业体系的,这些想象力,全部都写在R16里面。我们需要长期集中重兵攻坚它。”楚庆说。
过去近1年内,展锐与运营商在5G Rel-16技术方面进行了深入合作。今年7月30号,展锐与联通一起首发全球第一个R16的版本,另外,展锐与三大运营商共同做了切片的全链路的测试,获得了成功。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

加州大学洛杉矶分校、腾讯混元等推出Unify-Agent:一个能搜索全世界图片知识的AI画师
加州大学洛杉矶分校等机构联合推出的Unify-Agent突破了传统AI图像生成的知识局限,通过整合"思考-搜索-整理-绘制"四步工作流程,让AI画师具备主动查找资料的能力。该系统在FactIP基准测试中相关性指标提升61%,特别擅长处理需要准确世界知识的长尾内容和文化特色图像生成任务。

中科院团队首创FlowPIE:让AI像进化生物一样自动"孵化"科学创意,告别千篇一律的研究思路
中科院团队开发的FlowPIE系统首次将动态文献探索与创意进化相结合,突破传统AI科学创意生成的同质化局限。该系统通过流引导蒙特卡洛树搜索实现文献检索与创意生成的紧密耦合,并采用类生物进化机制持续优化创意质量。实验显示,FlowPIE在新颖性、可行性等维度显著超越现有方法,展现出强大的跨领域泛化能力,为AI辅助科研开辟了新路径。

阿里巴巴DAMO院推出虚拟细胞世界:Lingshu-Cell让单细胞生物学迎来AI革命
阿里巴巴DAMO研究院推出Lingshu-Cell虚拟细胞建模系统,采用掩码离散扩散模型技术,能够精确模拟和预测细胞在基因编辑、药物刺激等干预下的反应。该系统在国际虚拟细胞挑战赛中表现出色,为个性化医疗和药物开发开辟了全新路径,标志着数字生物学时代的到来。

上海AI实验室推出GEMS:让小模型也能像大师一样生成完美图像
上海AI实验室联合多所高校发布GEMS技术,通过智能团队协作机制让60亿参数的小模型在图像生成上超越顶级商业模型。该系统包含循环优化、记忆管理和技能库三大核心,采用多轮迭代和专业技能匹配,在主流测试中提升14分以上,为资源受限环境下的高质量AI应用提供新方案。

加州大学洛杉矶分校、腾讯混元等推出Unify-Agent:一个能搜索全世界图片知识的AI画师

中科院团队首创FlowPIE:让AI像进化生物一样自动"孵化"科学创意,告别千篇一律的研究思路

阿里巴巴DAMO院推出虚拟细胞世界:Lingshu-Cell让单细胞生物学迎来AI革命

上海AI实验室推出GEMS:让小模型也能像大师一样生成完美图像

周雅
主编
