 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
第二代骁龙8的高通AI引擎荣获2023世界人工智能大会SAIL奖
7月6日,2023世界人工智能大会(WAIC)在上海正式开幕。本届大会的主题是“智联世界,生成未来”。来自本届WAIC首日公开消息:第二代骁龙8移动平台的高通AI引擎荣获2023世界人工智能大会顶级奖项:SAIL奖——卓越人工智能引领者奖。高通公司全球副总裁侯明娟上台领奖。


第二代骁龙8凭借面向整个平台的开创性AI智能设计赋能了非凡用户体验,树立了网联计算的新标杆,其搭载高通技术公司处理速度最快、最先进的高通AI引擎,通过软硬件的一系列创新,相较上一代带来4.35倍的AI性能提升和60%的能效提升,从而为越来越多的创新型AI用例和AI增强的用户体验提供强大的性能基础。
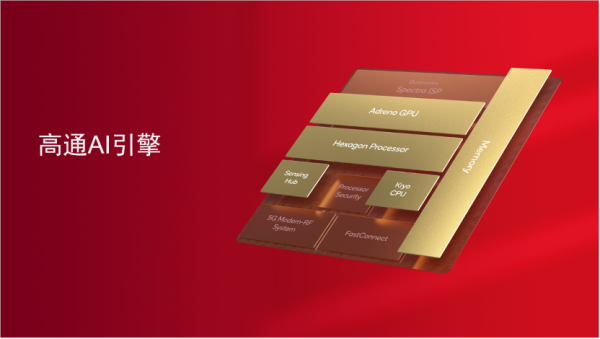
高通AI引擎由多个硬件和软件组件组成,用于在骁龙移动平台上为终端侧AI推理加速。它采用异构计算架构,包括高通Hexagon处理器、Adreno GPU、Kryo CPU和传感器中枢,共同支持在终端上快速而有效的运行AI应用程序。其关键核心Hexagon处理器拥有一系列创新:提供专用供电系统、支持微切片推理、INT4精度、Transformer网络加速等,可结合高通AI软件栈和AI Studio提供全栈AI能力和优化手段,行业内率先在终端侧支持Stable Diffusion、ControlNet等生成式AI用例,并可与云端协同打造适应大模型时代的混合AI处理框架,助力AI体验创新和生态繁荣。目前,第二代骁龙8移动平台已经可以支持参数超过10亿的AI模型运行。未来几个月内,将有望支持参数超过100亿的模型在终端侧运行,这也将成为基于高通技术的产品的一大差异化优势。
终端侧AI处理可以带来处理时延,隐私和安全,可靠性等优势,并且在生成式AI场景下可以有效分担云端处理的负载,降低成本和能耗,有助于云端协同的混合式AI处理架构的有效部署。高通AI引擎可提供卓越的终端侧AI处理能力,并可跨越智能手机赋能更多边缘移动终端类别,比如笔记本电脑、XR头显、IoT设备以及汽车等,引领终端侧AI应用的进一步发展。
据悉,高通深耕AI研发已超过15年,高通AI Research在基础研究领域实现突破,并跨终端和行业进行扩展,以赋能智能网联边缘。高通AI Research不仅在开展全新AI研究工作,也率先在商用终端上展示概念验证,为在现实世界中的技术规模化应用铺平道路。高通AI Research的重要AI研究论文正在影响整个行业,推动高能效AI发展,并与公司所有团队通力合作,将最新AI发展成果和技术集成到高通产品之中,让实验室研究所实现的AI进步能够更快交付,丰富人们的生活。
在WAIC现场,高通还带来了Stable Diffusion、ControlNet等生成式AI用例的技术展示。这是全球首个运行在Android手机上的Stable Diffusion终端侧演示,和全球最快的手机上的ControlNet终端侧演示。
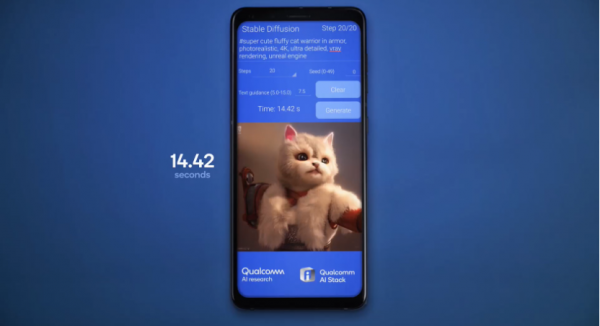
全球首个运行在Android手机上的Stable Diffusion终端侧演示
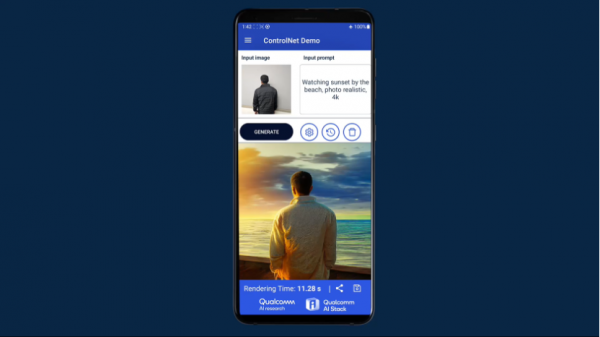
全球最快的手机上的ControlNet终端侧演示
Stable Diffusion是一个非常出色的从文本到图像的生成式AI模型,能够基于任何文本输入,在数十秒内创作出逼真图像。其参数超过10亿,迄今为止主要限于在云端运行。高通采用全栈AI优化的方式,通过量化、编译和硬件加速进行优化,使其能在搭载第二代骁龙8移动平台的手机上运行,在15秒内执行20步推理,生成一张512x512像素的图像。这是在智能手机上最快的推理速度,能媲美云端时延,且用户文本输入完全不受限制。目前,高通也已经将Stable Diffusion这一生成式AI用例扩展到搭载骁龙计算平台的PC产品上。
ControlNet图像生成图像模型是一项语言-视觉模型(LVM),拥有15亿参数,能够通过调整输入图像和输入文本描述,更精准地控制生成图像。在这项演示中,ControlNet能够在终端侧实现高效交互运行,通过一套跨模型架构、AI软件和神经网络硬件加速器的全栈式AI优化,时延12秒内可完成16步推理,生成AI图像,无需访问任何云端,便能提供高效、有趣、可靠且私密的交互式用户体验。高通AI模型增效工具包、高通AI软件栈和高通AI引擎在此过程中发挥了关键作用。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题
本文介绍了由南方科技大学等机构于2026年4月发表的研究(arXiv:2604.08865),提出了名为SPPO的大模型推理训练新方法。该方法将推理任务重新建模为"序列级情境赌博机",用一个轻量级价值模型预测题目难度,以单次采样替代GRPO的多次采样,解决了标准PPO的"尾部效应"问题。实验显示,SPPO在数学基准测试上超越GRPO,训练速度提升约5.9倍,配合小尺寸价值模型还能显著降低显存占用。

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半
这项由香港科技大学数学系完成的研究(arXiv:2604.10465,2026年ICLR博客论文赛道)提出了一种从朗之万动力学视角理解扩散模型的统一框架。研究指出,扩散模型的前向加噪和逆向去噪过程,本质上是朗之万动力学这一"分布恒等操作"被拆成了两半。在这个视角下,VP、VE-Karras和Flow Matching等不同参数化的模型可被精确互译,SDE与ODE版本可被统一解释,扩散模型相对VAE的理论优势得以阐明,Flow Matching与得分匹配的等价性也得到了严格论证。

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?
中国人民大学高岭人工智能学院等机构联合开发了AiScientist系统,旨在让AI自主完成机器学习研究的完整工程流程,包括读论文、搭环境、写代码、跑实验和迭代调试,全程无需人工干预。系统核心设计是"薄控制、厚状态":由轻量指挥官协调专业代理团队,通过"文件即通道"机制将所有中间成果持久化存储,使每轮工作都能建立在前一轮积累的基础上。在PaperBench和MLE-Bench Lite两个基准上,系统表现显著优于现有最强对比系统,论文发布于2026年4月。

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
这项由字节跳动发布的研究(arXiv:2604.13030)提出了生成式精化网络(GRN),一套模仿人类画家"边画边改"直觉的视觉生成新框架。其核心包括两项创新:层级二进制量化(HBQ)通过多轮二分逼近实现近乎无损的离散图像编码,以及全局精化机制允许模型在每一步对整张图像的所有位置重新预测并随时纠错,从根本上解决了自回归模型的误差积累问题。配合基于熵值的自适应步数调度,GRN在ImageNet图像重建(rFID 0.56)和生成(gFID 1.81)上均创下新纪录,并在文本生成图像和视频任务上以20亿参数达到同等规模方法的领先水平。

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
