 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
新晋“学霸”夸克大模型拿下C-Eval和CMMLU双榜第一
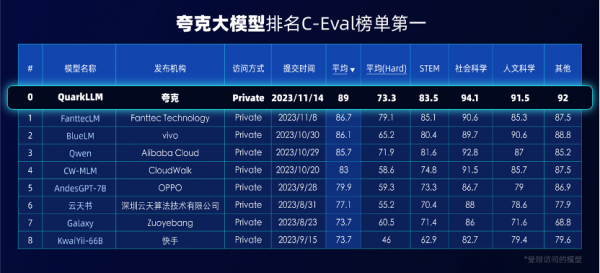
11月16日,根据最新成绩,千亿级参数的夸克大模型登顶C-Eval和CMMLU两大权威评测榜单,多项性能优于GPT-4。在国内大模型赛道火热的当下,夸克自研大模型凭借过硬的研发能力及数据、行业、平台等优势成为新晋“学霸”。
作为国内最权威的两个大语言模型测试榜单,C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的综合性考试评测集,覆盖52个学科,是目前权威的中文AI大模型评测榜单之一。CMMLU 是由MBZUAI、上海交通大学、微软亚洲研究院共同推出,包含67个主题,专门用于评估语言模型在中文语境下的知识和推理能力。
评测过程中,夸克大模型经过了上万道专业考题的检验,覆盖几十个学科和不同学段。无论是常识问题还是社会科学知识,夸克大模型都展现出了处理复杂、多层次问题的能力。基于精调后的训练数据,夸克大模型能够更好地理解问题的上下文、逻辑结构和语义关系,从而更全面、深入地分析和解决问题。
在CMMLU榜单评测中,夸克大模型以平均77.08分的成绩位列总成绩第一,并占据社会科学和其他两个类目的首位。在C-Eval榜单中,夸克大模型平均分达到89分,稳居行业第一,同时在社会科学、人文科学和其他三个类目中位列榜首。夸克大模型同时登顶两大权威榜单,也进一步证明夸克在数据增强、模型选择、训练策略、模型融合以及模型评估上,处在行业领先地位。

同时,在国内专业考试测试中,夸克大模型的表现堪称“学霸”。不仅在中考、高考、研究生考试中超过GPT-4,包括临床执业医师资格考试、计算机等级考试、公务员考试、教师资格证考试等评测中均优于GPT-4。具备超强解题能力的夸克大模型,应用在日常学习、工作场景,有望给用户带来效率上的全面提升。
此外,夸克大模型还拥有强大的文学创作能力,能够根据用户提供的主题或关键词,生成连贯、有逻辑、有深度的文本内容,可以帮助用户撰写文章、新闻、诗歌等各类文本,支持续写、润色、仿写、批改等多种不同写作需求,进一步提高用户的创作效率。
据介绍,凭借数据、行业、知识正确性、平台等四大优势,夸克大模型应用会优先落地在通识问答、专业搜索等信息服务领域,满足年轻人学习知识和提升自我的需求。夸克将借助自研大模型全面升级,为年轻人工作、学习、生活提供更全面的服务。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
