 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
谷歌官宣Gemini 3,团队揭秘模型训练的两个“Aha时刻”,哈萨比斯:“又向AGI迈进一步”

作者|周雅
“Gemini 3的发布 ,代表团队在通往AGI(通用人工智能)路上迈出的又一步。”太平洋时间11月18日8:00,谷歌正式发布Gemini 3,Google DeepMind 首席执行官 Demis Hassabis 在谷歌博客中写道。

而就在一天前,谷歌举行了全球媒体沟通会,当被问及模型训练过程中的“Aha Moment(啊哈时刻/顿悟时刻)”时,Google DeepMind Gemini产品管理高级总监Tulsee Doshi,负责Gemini研发工作的她分享了两个瞬间。
第一个瞬间,是她第一次尝试可视化编码时,仅用非常简单的自然语言提示词,Gemini 3就能创造出一款游戏,甚至是可交互的3D可视化效果,还能在那个环境里“真的玩起来”。
第二个瞬间则更具人文色彩。Tulsee尝试让模型处理一首用“古吉拉特语”写成的诗,那是她父母的母语,不仅要求模型做翻译,还让它二次创作。“你能看到模型的细腻感、创造力、以及写作风格,我当时就觉得:哇,这个模型真的很聪明,能把很多元素融会贯通。”
这两个时刻,一个关乎创造,一个关乎理解,似乎都在指向这是一种更接近人类直觉的智能。Tulsee告诉我们,“当你把多模态输入、复杂推理问题,以及你想要的输出形式结合起来时,Gemini 3 的魔力就显现出来了。”
解构Gemini 3
梳理Gemini 3 的核心进步,可以概括为三个层面:推理能力、多模态理解能力、编程能力。

Google DeepMind首席技术官Koray Kavukcuoglu在媒体沟通会上这样描述Gemini 3的交流风格——“Gemini 3给出的回答聪明、简洁、直截了当。”
这种质变建立在「推理能力」之上。
在LMSys Elo Arena排行榜上,Gemini 3 Pro 以1501分的突破性分数登顶,比其前代 Gemini 2.5 Pro 高出50个等级分;此外,在更考验深层理解的基准测试中,它的表现同样突出:在GPQA Diamonds(一个衡量研究生水平推理与知识的基准测试)达到91.9%的准确率;在Humanity’s Last Exam(一个要求多步逻辑和专家级推理的基准测试),不使用任何外部工具,Gemini 3 Pro 取得了37.5%的成绩。
这些数字背后,是模型正在往解决复杂问题的能力跃迁,它意味着 Gemini 3/Pro 在处理科学、数学等专业领域的复杂问题时,具备了更高可靠性。
为了进一步突破,谷歌还推出了一个名为 Gemini 3 Deep Think(深度思考) 的增强推理模式。在内部测试中,Gemini 3 Deep Think 在Humanity's Last Exam(未使用工具时为 41.0%)和 GPQA Diamond(93.8%)中的表现,甚至还要优于 Gemini 3 Pro。
我们再来看Gemini 3的多模态理解能力。
Google与 Alphabet 首席执行官 Sundar Pichai 在谷歌博客中写道:“近两年前,我们开启了Gemini时代,这是我们公司有史以来最大的科学和产品项目之一。仅仅两年时间,人工智能就从单纯阅读文本和图像发展到能够读懂房间。”
“读懂房间”(reading the room)这个比喻,精准描述了 Gemini 3 在多模态理解上的进步。它不再是单一地处理文本、图像或音频,而是能够原生且无缝地理解这些信息模态之间的内在联系和细微差别。
根据官方数据,Gemini 3 Pro 在衡量多模态能力的基准 MMMU-Pro 和 Video-MMMU 上,分别取得了81%和87.6%的分数,成为“世界上最先进的多模态理解模型”。
这意味着什么?在实际应用中,用户可以向 Gemini 3 提供一段长达数小时的视频讲座,让它生成交互式的抽认卡帮助学习;可以上传一张手写的,甚至混杂着不同语言的家庭食谱照片,让它整理并翻译成可分享的电子版;甚至可以上传一段自己打球的视频,让模型分析动作并生成改进的训练计划。
这种能力,是谷歌从 Gemini 1.0 时代就确立的原则——原生多模态与长上下文,它让AI的输入和输出变得灵活,从而适应用户的个性化需求。
我们最后来看Gemini的编程能力。
如果说推理和多模态是 Gemini 3 的“大脑”,那么其强大的编程和规划能力就是它的“双手”,谷歌将此定义为“代理式编程(Agentic Coding)”和“可视化编程(Vibe Coding)”,借此重新定义用户与信息的交互方式、开发者与机器的协作模式。
“Vibe Coding”,也就是大家常说的氛围编程,这里的关键在于“Vibe”——一个模糊、感性的词,它指向的是一种全新的创造流程:用户提供一个抽象的想法、一种“感觉”或“氛围”,而AI则将其直接翻译成一个功能完备、视觉丰富、可交互的数字实体,可以理解为让开发“所见即所得”。
正如Tulsee的“啊哈时刻”所展示的,这指的是模型仅通过自然语言描述,就能生成丰富、美观、可交互的前端界面或应用。Gemini 3 Pro 在这方面实现了飞跃,能够处理更复杂的指令,渲染出更具交互性的网页。
如果说“可视化编程”(Agentic Coding)是Gemini 3引人注目的前台魔术,那么“代理式编程”(Agentic Coding)则是驱动其自主行动的后台引擎。
代理式编程(Agentic Coding),核心是赋予AI模型规划、拆解复杂任务、并自主调用工具(APIs、浏览器、本地文件系统)来完成任务的能力,它不再是一个被动回答问题的聊天机器人,而是一个可以被授权代表用户执行多步骤工作流的“数字代理”。
Google Gemini应用产品管理副总裁Chris Shuhar在沟通会上举例说:“像买演唱会门票这类事,以前要到处找各种信息,现在我可以让「代理」去找,帮我配好合适的组合,把流程推进到可以买票的那一步,然后我只需要一键确认就行。”
对于企业而言,“代理式编程”的意义更为深远。谷歌云AI副总裁兼总经理Saurabh Tiwary在谷歌博客中指出:“企业现在可以利用Gemini 3执行财务规划、供应链调整和合同评估等任务。”
谷歌的合作伙伴也印证了这一点。Shopify首席技术官Mikhail Parakhin表示:“这一进步加速了Shopify构建代理式AI工具的能力,解决我们商户复杂的商业挑战。”汤森路透首席技术官Joel Harlon则提到,他们在法律推理和复杂合同理解方面取得了“可衡量的、显著的进展”。
综合来看,Gemini 3 不只是一个被动响应指令的工具,它被设计成一个主动的、有规划能力的“伙伴”或“代理”,能够理解复杂目标,拆解多步任务,并自主执行。这一特性,正是谷歌重塑其核心产品与开发者生态的基石。

体验的重构:AI如何进入你的日常?
拥有了如此强大的智能,接下来的关键问题是:谷歌打算如何将其交付给数十亿用户?答案并非简单地更新一个应用,而是从根本上重构用户与信息交互的“体验”。谷歌搜索和 Gemini 应用,成为了这场变革的前沿阵地。
1、当Gemini 3引入谷歌搜索:从“答案引擎”到“发现与创造引擎”。
“这是我们首次从第一天起就在谷歌搜索中上线Gemini 3。” 谷歌搜索部门产品副总裁Robby Stein在会上强调。这一举动意义重大,它标志着谷歌最核心的产品,正在被最前沿的AI模型深度重塑。
首先,Gemini 3让搜索不再只是“回答问题”。
举个例子:一个关于冲浪的问题,涉及天气、海况、租赁、去哪儿、时间安排等多个方面,Gemini 3会进行推理、做检索、构建整页信息,从谷歌地图数据库中直接拉取地点信息,给到出行安排建议。
那么,Gemini是如何找到这些可靠信息的呢?
谷歌有个技术叫“查询扇出(query fan)”:当用户提出一个复杂问题,Gemini 3 不再只是寻找单一答案,它会将这个问题“扇出”数十个更细分的查询,在底层进行大量检索,综合来自全网、知识图谱(包含万亿级事实)、谷歌地图(数亿地点)和谷歌产品数据库(数十亿产品)的信息,最终构建出一个包含地点建议、时间安排、地图信息的完整规划页面。这让搜索从“回答”走向了“规划”。
其次,Gemini 3让搜索实现了“生成式用户界面”(Generative UI)。
这是我认为 Gemini 3 带来的最具变革性的体验,AI 不再只是生成内容,它开始实时动态生成一个为你的搜索量身定制的可视化界面。
假如你正在搜索“受力分析背后的物理原理”时,传统的搜索引擎会给你链接、文本和视频。而由Gemini 3驱动的搜索引擎则更进一步,它不仅生成文字解释,更实时编写并渲染了一个交互式模拟器:比如“三个行星在海洋中”的系统,展示它们的物理运行机制,甚至包括当你向环境引入“混沌”时会发生什么。“借助 Gemini 3,你将‘看见并交互’以往无法做到的抽象概念,从而学习任何东西。”Robby指出。
谷歌搜索副总裁 Elizabeth Reid 指出,这些由 Gemini 3 实时生成的动态布局、互动工具和模拟,正在将搜索变成一个强大的“发现引擎”和“学习引擎”,让用户能够“看见并交互”以往无法做到的抽象概念。
对于普通用户,这意味着信息获取从“阅读”升级为“体验”。学习物理定律不再是背诵公式,而是亲手操作模拟器;规划旅行不再是整理列表,而是浏览一本动态生成的旅行手册。这极大地提升了用户粘性和产品体验的丰富度。
对于开发者和创作者,这意味着原型设计的门槛被无限拉低。一个独立开发者或产品经理,可以在几秒钟内将一个模糊的想法变成一个可点击、可演示的应用,极大地加速了创新迭代的速度。
2、当Gemini 3引入Gemini 应用:迈向真正的通用代理。
作为谷歌AI能力的集中体现,Gemini应用的月活跃用户已从上一季度的4.5亿增长至6.5亿。Gemini 3 的到来,则为其注入了更强大的动力,并带来了两个实验性的新方向。
第一个是动态视图(Dynamic Views)。在Gemini应用中,当用户提出一个需求,比如“为每件作品解释梵高画廊的生活背景”,Gemini 3会利用其“代理式编码”能力,实时设计并编写一个定制化的用户界面。用户得到的不再是静态文本,而是一个可以点击、滚动来探索的交互式画廊。
第二个是视觉布局(Visual Layouts)。同样在Gemini应用中,当用户提出“计划明年夏天去罗马三天的旅行”时,模型会生成一个沉浸式的、杂志风格的可视化行程,其中包含图片、地图模块和可交互的日程。
第三个是Gemini Agent。这项面向 Google AI Ultra 订阅用户的实验性功能,允许 Gemini 直接处理多步骤任务,它连接用户的 Google 应用,完成管理日历、添加提醒、整理收件箱等琐事,且经过你批准后可以优先处理待办事项和草拟回复。你也可以给出具体指示,比如:“用邮件里的信息帮我预订一辆中型 SUV,价格在每天 80 美元以下。”Gemini 会查找你的航班信息,在预算内安排预订。
谷歌方面指出,即日起, 美国的 Google AI Pro 和 Ultra 用户 可以通过在 AI Mode模式的下拉菜单中选择“思考(Thinking)”,即可体验 Gemini 3 系列首款型号 Gemini 3 Pro,包括生成式UI等体验。很快,将在美国所有用户中推出 Gemini 3 的 AI Mode模式。
开发者和企业的“谷歌反重力”
如果说在消费端,Gemini 3 致力于重构“用户体验”;那么在开发者和企业端,它的目标则是重塑“生产力范式”。为此,谷歌推出了一个全新的、命名极具野心的平台——Google AntiGravity(谷歌反重力)。
“我们想推动‘模型与IDE(集成开发环境)如何协同工作’的前沿,让软件工程师的生产力显著提升。”Koray Kavukcuoglu 强调。

“谷歌反重力”不是对现有 IDE 的简单改良,而是一个全新的“智能体开发平台”。平台中,“代理或智能体”被提升到一个专门的界面,拥有与开发者平等的地位,它不再是编辑器里的一个插件,而是一个可以自主访问编辑器、终端、甚至内置浏览器的“伙伴”。
有了该平台,开发者不再需要逐行编写或调试代码,而是可以在更高的抽象层级下达“任务”。例如,开发者只需给出一个高层级的提示:“创建一个航班跟踪的Web应用”。接到任务后,“谷歌反重力”平台中的 Gemini 3 会自主将其分解为子任务,规划执行路径,并开始编程,它会在 Chrome 浏览器中启动应用来自我校验,并在关键节点生成进度报告,向开发者寻求确认。随着使用,系统会学习开发者的架构偏好和编码风格,在后续项目中变得越来越默契。
Koray进一步向我们阐明了“谷歌反重力”的战略定位。它是谷歌与开发者直接互动、理解其工作流与挑战的“触点”,通过这个平台收集到的反馈,将反过来打磨谷歌的模型,使其更适合“以智能体为中心”的开发模式。这形成了一个研发闭环。
除了“谷歌反重力”这一旗舰项目,Gemini 3 的编程能力也通过 API 全面开放,并已集成到 Cursor、GitHub、JetBrains、Replit 等第三方平台。Shopify 首席技术官 Mikhail Parakhin 对此表示:“这一进步加速了 Shopify 构建代理型 AI 工具的能力,以解决我们商户复杂的商业挑战。”
这也标志着软件开发的逻辑正在发生深刻变化,开发者正在从“代码的编写者”转变为“代理的指挥者”,工作的重心从繁琐的实现细节,转移到更高层级的架构设计和创意构想。
谷歌的全栈赌注与速度之争
在发布会的每一个环节,从模型研发到产品落地,谷歌的发言人反复强调一个词:“全栈”(full-stack)。这是一个技术术语,也是理解谷歌AI战略、乃至其在激烈竞争中保持领先的关键钥匙。
所谓“全栈”,通俗解释是指一个从硬件到软件、从研究到产品的垂直整合体系。对应到谷歌是四个层面的能力:在硬件层,谷歌自研的 TPU 芯片和专为大规模训练设计的数据中心与计算集群(Pod)。在研究层,以 Google DeepMind 为核心的世界级前沿研究,产出如 AlphaFold 等诺贝尔奖级别的成果。在模型与工具层,谷歌基于强大的硬件和研究能力,开发出像 Gemini 这样的基础模型。在产品与平台层,谷歌将模型能力迅速、深度地整合到谷歌搜索、云、Gemini应用等触达数十亿用户的产品中。
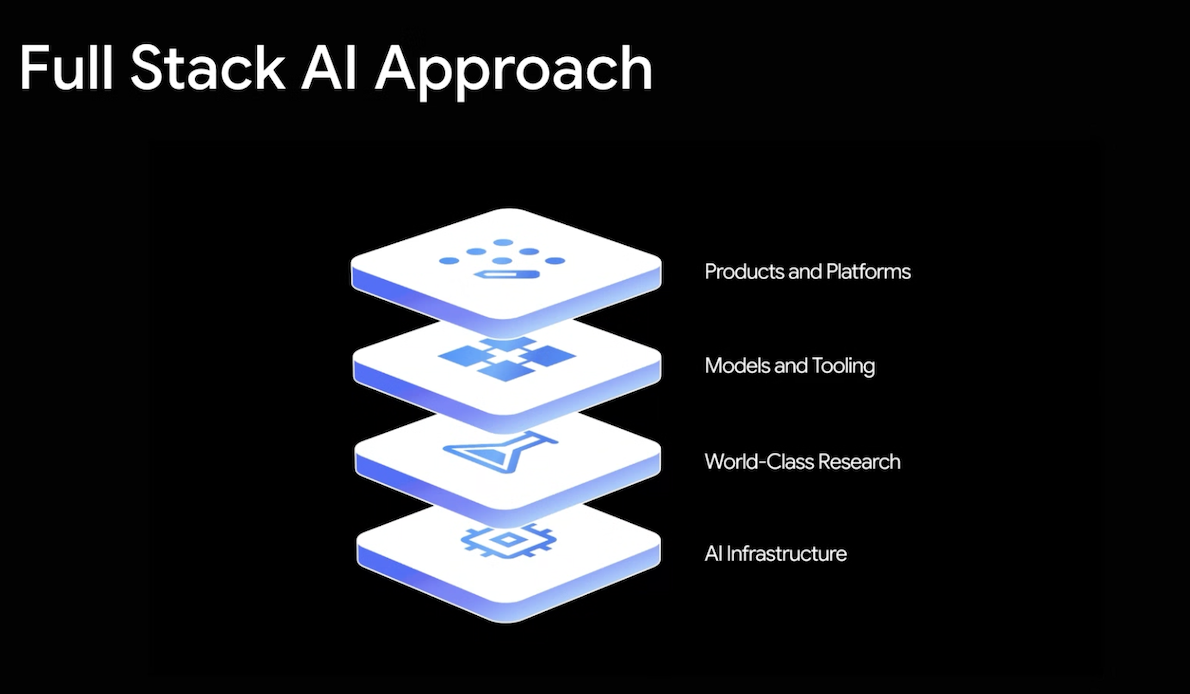
这种“全栈”路径的最大优势在于“速度”和“协同”。正如Robby所说,它能“大幅缩短‘模型开发完成’与‘在产品中展示给大量用户’之间的时间”。Gemini 3 在发布首日即进入谷歌搜索,就是这一优势的直接证明。
Koray认为,衡量大模型进步的最好方式是看AI对各行业的实际影响。“在越来越多行业,越来越多职业中,员工用模型来辅助工作,学生用模型来辅助学习……模型在我们的日常生活中影响越来越大。”
他的言下之意是,单纯的模型参数或基准分数的增长曲线或许会变化,但由模型能力提升所驱动的“应用创新”和“价值创造”的速度并未放缓。谷歌的全栈路径,确保了模型能力的每一次提升,都能迅速转化为产品体验的改进和用户价值的增长,这本身就是一种速度。
这种速度与协同最终服务于商业。在企业端,Gemini 3 通过 Vertex AI 和 Gemini Enterprise 平台提供给企业客户。来自 Box、汤森路透、乐天集团等首发合作伙伴,验证了其在法律推理、合同分析、多模态数据处理等复杂商业场景中的价值。
通过将最强大的模型能力打包成企业级解决方案,谷歌正在构建一个从消费者洞察到企业服务的完整商业闭环。消费级产品(如搜索和Gemini应用)提供了海量用户数据和真实应用场景,用于迭代模型;而企业级服务,则将这些经过验证的强大能力商业化,创造直接收入。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升

周雅
主编
