 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
他曾经用大数据知道了地球上有多少棵树,现在AI知道内蒙养牛该去哪割草

CNET科技行者 9月8日 北京消息(文/孙封蕾): 十几年前,还在北京大学读研究生的张弓,来到呼伦贝尔大草原的做土壤水分勘测的时候,呼伦贝尔大草原的草有一米高,行走在草里面就像在大海里冲浪,当他2015年再来到这片草原的同一块草地上,草不再高,甚至出现了土壤裸露的情况。于是,当时在NASA工作的他,决定回到中国,创办了北京佳格天地科技有限公司,通过新的空间技术,服务中国农业、环境、生态等领域。
有一家企业在内蒙从事草场运营的企业,他们大规模种草的企业,并把草收割回来作为饲料,服务于畜牧业——养牛,最终变成大众消费的奶制品。就是这样一家企业找到了佳格,利用佳格的技术来判断什么时候割草,什么地方的草能打,什么地方的草不能打,什么时候来种草,要种多少草。
过去的畜牧业发展,处于很低的水平,过度的放牧带来了土地沙化等问题,虽然短期获得了经济效益,而长期来看,破坏了生态,更是导致无草可打。
同样在内蒙古,阿里云帮助内蒙古环保厅建成了内蒙古的环境大脑,用人工智能的方式保护内蒙古的“羊煤土气”。
内蒙古有着丰富的矿产资源,在开发中没有注意到环境保护,就带来了草场退化、沙漠化等环境倒退的事实。在内蒙古有很多企业,对这些企业进行排污监管,也是阿里云ET环境大脑的工作之一。
阿里云帮助内蒙古环保厅构建了排污许可大数据平台,根据企业的产量、能耗、规模等进行评估,构建全区企业环境信用体系,给相关政府提供支持和预防信息的依据。
不管是阿里云,还是张弓所创立的佳格公司,他们做依据的基础都是来自卫星遥感图。
阿里云提供了两张卫星摇杆图,一张是2000年东北夏季植被,一个是2017年东北夏季植被,一个是内蒙古大草原,一个是鄂尔多斯草原。橘色部分是植被退化,绿色部分是植被自然恢复,这些是用肉眼可以看到的。

图1:卫星遥感图上看到的植被情况
实际上,利用人工智能,是可以数出这一片地区有多少棵树!
张弓介绍,在NASA,他看到的地球图像都是一道一道的,更像是激光,通过卫星扫描,可以看到中国西部有很多地方是完全没有植被,裸露的大地,这些沙被风刮起了就会形成这样的效果。
在美国工作的时候,张弓他们就用卫星和无人机来取做识别,试图把美国所有的树都数出来,最终知道地球上究竟有多少棵树。他们利用架设在太空的照相机“天眼”发回的地面图像,不停的做比对,用图像识别的方法来提取数据。
然而,机器在识别大树的时候,是有困难的,因为树有影子,阳光强烈的时候,大树周围有各种各样的影子,是很难被机器判断的。他们不得不开始寻求新的方法来尝试。
后来,他们就利用树木可以固定碳的方法,来计算有多少的能量被保护在商务圈里,而不是让这些二氧化碳在大气中吸收热量,每棵树、每个生物体都有固定的碳数量,树冠大,碳的含量就多,再用激光扫描的办法来查看整棵树有多高,从而构建树木的三维模型。

图2:根据碳含量标记“树”
通过这样的方法,他们标记出了美国优胜美地国家森林公园的一角,然而又标记出了加利福尼亚州有多少树,继而算出了美国有多少树,最终算出了地球上的树木数量——400241300201棵,精确到个位数。
图3:优胜美地的树木3D模型

图4:地球上有400241300201棵树
时间倒回一年前,支付宝里悄悄上线了一个“碳账户”,参与到支付宝的绿色金融活动,就可以得到一些碳能量,积少成多,就可以种树了。而支付宝用户会产生疑问,自己种下的这棵树,在支付宝的界面里看上去就是一颗颗卡通的树,很多人都怀疑自己种下的树是不是真的,都想知道自己种的树在哪里。虽然支付宝已经跟用户说,你的树在阿拉善,可究竟阿拉善的哪棵树是我贡献的呢?
而现在,用空间技术,用人工智能的分析手段,张弓他们可以帮支付宝的用户标记出,你的树在哪里,虽然在卫星上看只是一个星星点点。

图5:在卫星图片上看到的一棵棵“树”
这样的空间技术,加人工智能的手段,看上去更像是一种技术的奢侈品,那么现在,已经有人在想办法把这种奢侈品变成一种开放的能力。
在阿里巴巴95公益周“天更蓝”发布会上,阿里云宣布启动“青山绿水”计划,全面开放ET环境大脑的智能技术,提供全景生态分析、智能综合决策、智能环境监督等服务,目标是1年内赋能100家环保机构。
阿里云ET环境大脑负责人王晓光介绍,凭借阿里云飞天的计算能力和人工智能算法,环境大脑能够发现卫星图像、气温、风力、气压等各类信息背后的环境密码,并快速做出决策。
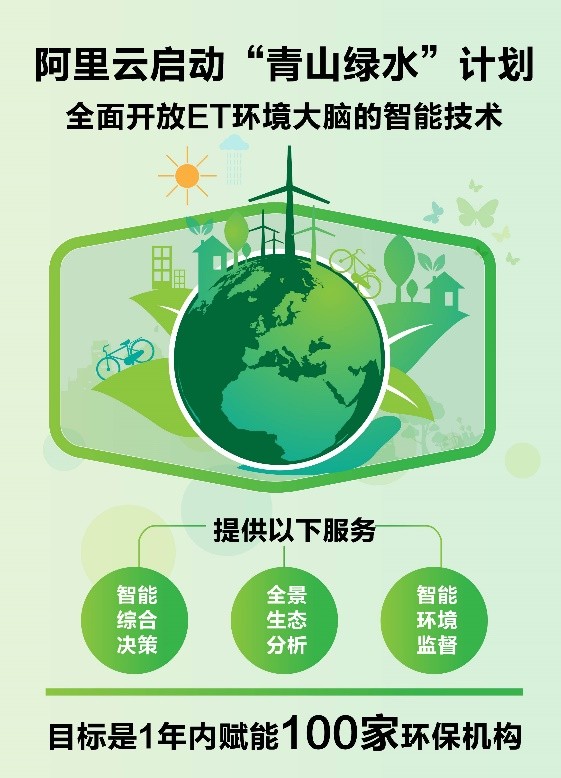
图6:阿里云的“青山绿水”计划


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案

孙封蕾
执行总编辑
