 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
高通创投沈劲:被投中国企业表现超预期 投资看重5G和AI

科技行者 6月12日 北京消息(文/周雅):6月11日,高通创投(Qualcomm Ventures)宣布对3家中国公司进行风险投资——设备连接方案服务提供商红茶移动,车载安全驾驶辅助系统提供商腾视科技,以及云游戏公司达龙云。
在当日举行的线上媒体沟通会上,高通公司副总裁、高通创投中国区董事总经理沈劲,最新介绍了高通创投的业务近况,包括“过去半年在中国投了什么”和“接下来将要投什么”。
高通创投成立于2000年,在全球7个地区设有团队,共有30余名投资经理,目前管理资金规模超过10亿美元,正在管理被投公司超过150家。
过去九年内,高通创投成功投资并完成退出13个估值超过10亿美元的独角兽企业。其中,2019年就有三家,即视频会议公司Zoom,在科创板上市的中微半导体,以及网络安全公司Cloudflare。
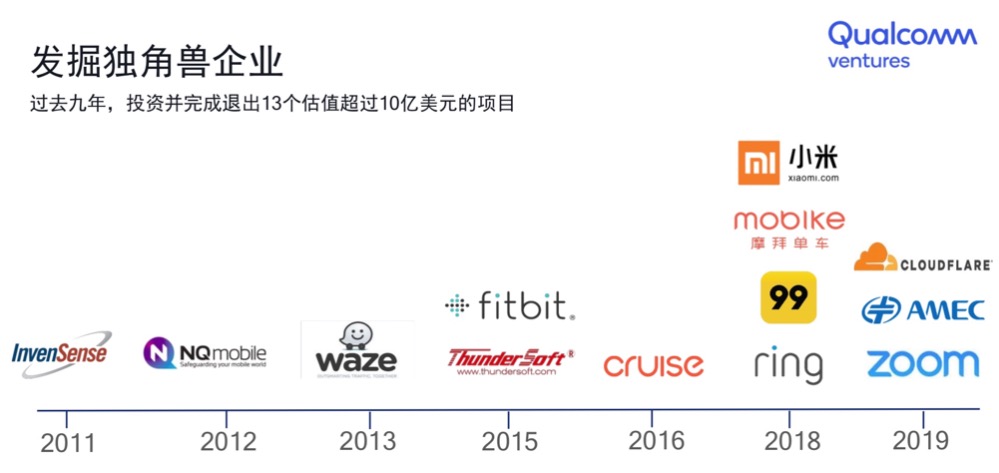
目前,高通创投在中国投资的企业已经超过60家(如下图)。沈劲指出:“中国市场对高通来讲一直是一个极为重要的市场,对高通创投也是如此。”

投资看重5G、AI领域应用与赋能
高通创投此次风投的3家中国公司,分别覆盖物联网、AI垂直应用和5G应用领域,均致力于利用前沿科技创造全新价值和体验。其中,腾视科技(Tensortec)成立于2017年,是一家智能辅助驾驶系统解决方案提供商,广泛应用在陆海空有驾驶人员的交通/工程设备上;红茶移动(Redtea Mobile)成立于2015年,一家解决5G时代蜂窝物联网海量部署的关键问题的连接方案提供商;达龙云成立于2010年,是一家以5G网络为引擎的云游戏公司。
谈到高通创投的最新投资,沈劲特别指出一个重要背景——全球5G发展势头非常强劲。
目前,全球60多家运营商已经部署5G商用网络,同时380多家运营商在119个国家力争投资5G建设。60多家OEM厂商已经推出或者宣布将推出5G终端,超过375款搭载高通骁龙解决方案的5G终端已经发布或正在设计中。5G快速发展,人工智能在应用层面也进入新阶段。
沈劲介绍:“高通创投整个投资理念,围绕「5G」和「AI」这两大赋能的技术展开。”
5G与AI“双轮驱动”,使智能不再只集中在云端,而是分布在网络边缘侧以及终端侧。以前,大数据和AI能力都只集中在云端,与终端的沟通时延超过100毫秒。而5G网络的普及以及站点密集程度的增加,能够将时延缩小到1毫秒。在终端侧,AI将快速普及,包括智能手机、大量物联网设备,未来都将具备AI能力。
2018年和2019年,高通创投先后设立1亿美元AI风险投资基金,和2亿美元5G生态系统风险投资基金,以持续推动万物智能互联生态系统的培育及扩展。
尽管5G应用遍地开花,但高通创投的投资有的放矢,主要投资四个领域:
-
边缘侧和终端侧的人工智能;
-
5G时代的多媒体和XR(扩展现实);
-
机器人和智能制造领域,包括自动驾驶和辅助驾驶;
-
物联网和车联网。
与此同时,高通创投也非常看好「5G在网络运营层和网络设备层」和「5G的核心元器件和5G的新形态终端」的投资。比如高通创投今年初投资的一家独角兽企业Affirmed Networks,就是用虚拟化和云端来创新网络设备管理的一家企业,现被微软收购。
“高通创投在中国的投资活跃度仅次于美国。”沈劲说,中国在5G赋能和应用领域的创新,尤其是在垂直行业应用的创新方面水平比较高。美国则在5G网络侧的创新比较活跃,例如网络设备、网络运营(包括5G专网运营)等方面。
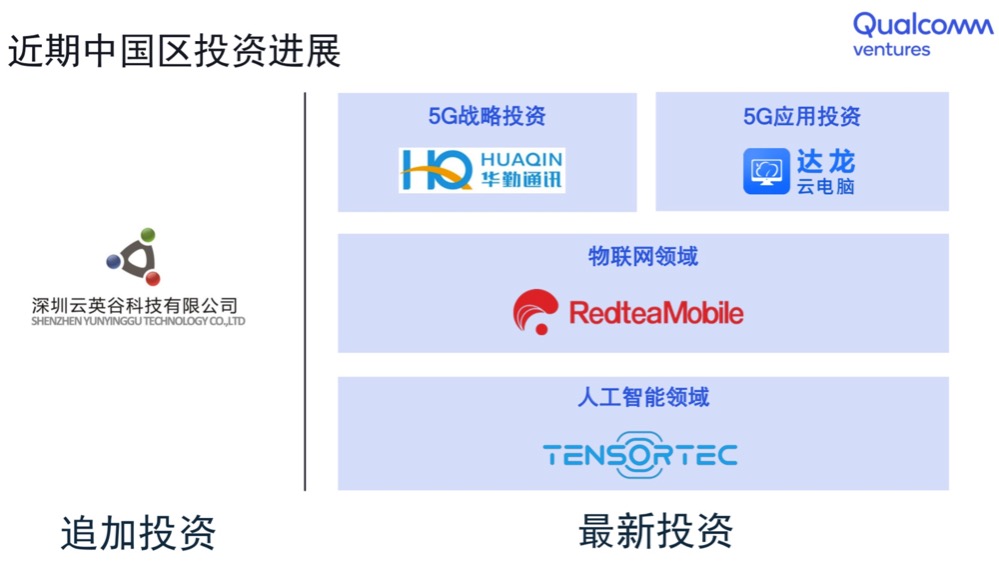

沈劲总结道,被投中国企业的整体表现和发展符合甚至超出预期,总体而言,对高通创投在中国市场的投资回报比较满意。
投资未因疫情放缓,或将追加
谈到疫情对高通创投的影响,沈劲坦言“没有受到疫情太大的影响,仍然完成了多家公司的最新投资”。他说,高通创投的投资数量,不会受到疫情影响,投资还有可能增加。
沈劲表示,去年底,高通创投设立了2020年投资目标,包括资金规模、企业数量等等。一个多月前,又重新进行了评估,考虑在疫情影响下是否要调整投资计划。但现在看来,不需要调整,能够完成目标。
沈劲解释原因,因为高通创投投资的领域,在疫情影响下被市场看好。
一方面,新基建首要领域就是5G。另一方面,高通公司在移动连接和计算领域,有很深的技术积累,疫情期间的数据使用量比疫情前更大,人们也更加依赖于连接。
“总体而言,VC(创投基金)目前的投资是趋于谨慎的,但高通创投(属于CVC,即企业风险投资)目前还在非常积极地投资。从此次宣布的几家被投公司,以及过去几个月的投资情况来看,高通创投的投资节奏没有放慢。”沈劲说。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升

周雅
主编
