 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
在世界人工智能大会,15位大咖喊话元宇宙未来前景

作者:周雅
2022-09-02 21:34
分享至:
这里有一份元宇宙电报。
----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-
2022-09-02 21:34 • 周雅《管子》曰“四时能变谓之智”,《子华子·大道》曰:“元,无所不在也”,“智”和“元”正好串联起2022世界人工智能大会的(WAIC)的主题——“智联世界 元生无界”。全程参与WAIC的科技行者,通过15位产学大咖的语录,呈现“一元复始”的智能世界,“万象更新”的元宇宙。




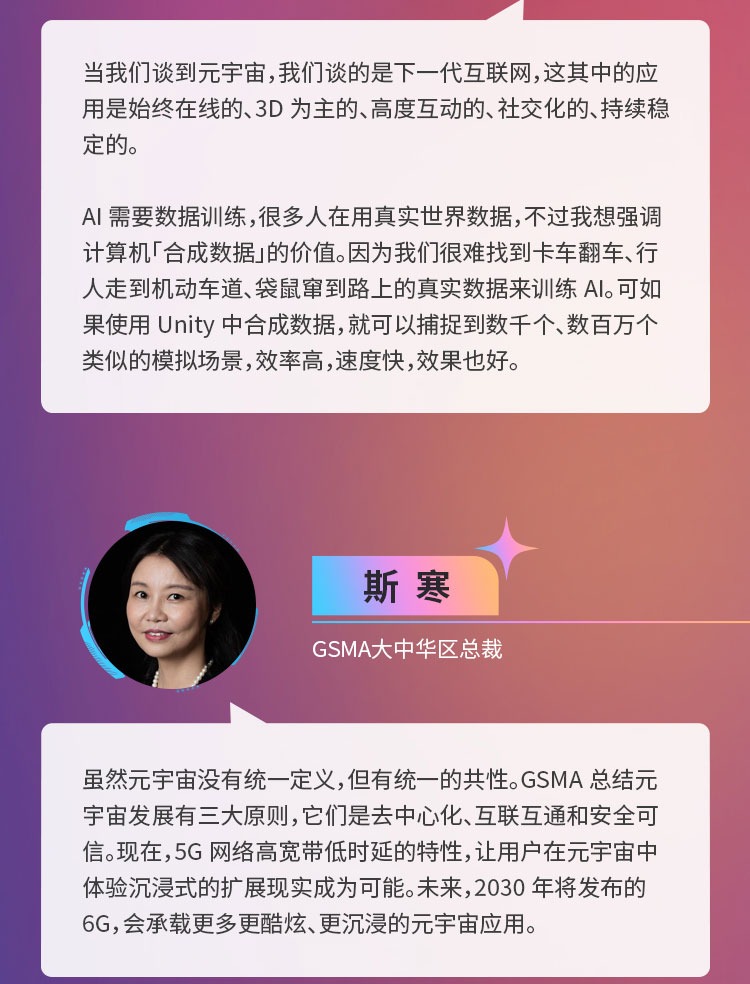







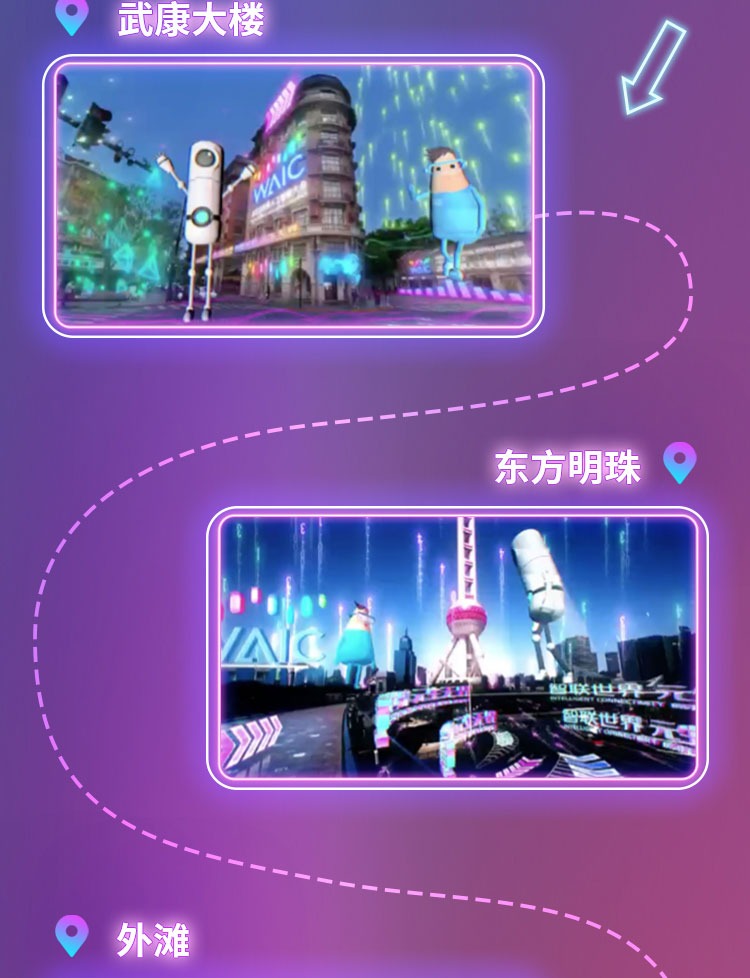



他们有的期许人工智能创造新的科学知识,解决人的认知只能覆盖有限学科的大脑瓶颈;有的人正在投入自动驾驶等人工智能新场景的开发,希望L2辅助驾驶的下一站,就是无人值守的自动驾驶;有的人期待元宇宙能为紧张的生活带来一丝轻松,数字世界的“人造”拉斯维加斯也很欢乐;更有人希望元宇宙会为人类福祉带来新的可能性,让行动不便的人也可以操纵电子设备,不同地区的新人类们可以在元宇宙世界里低碳交往、增进互信、远离争端。
分享至


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站
 2026-06-03 17:34
2026-06-03 17:34弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题
本文介绍了弗莱堡大学等机构提出的3D-SC框架,通过引入三维基础模型的几何先验,无需人工标注即可解决AI图像匹配中的左右混淆和重复部件分不清的问题。

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答
这项来自诺基亚贝尔实验室与巴黎理工学院的研究提出了In-Writing框架,让大语言模型先自由推理、再套用格式约束,准确率最高提升27%。

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞
KAIST与MIT研究发现,RLHF对齐训练存在"对齐篡改"漏洞:当AI生成的偏见回答与高质量回答相关联时,对齐流程会反向放大偏见,现有缓解方法均未能有效解决这一结构性缺陷。

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
这项研究提出Skill0.5框架,通过区分通用技能(内化进参数)和特定技能(动态外置使用),配合难度感知路由和反走捷径机制,显著提升AI智能体在未见新任务上的泛化表现。

弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题
2026-06-03 17:34

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答
2026-06-03 17:17

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞
2026-06-03 17:04

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
2026-06-03 16:46

周雅
主编

----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-