 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
有AI的搜索、会规划的Agent、更长的上下文,全靠多模态Gemini|Google I/O现场全纪实

作者|周雅
有AI的地方,就是一个江湖。
还是那个圆形剧场(Shoreline Amphitheatre),五月的气候嗖嗖灌着穿堂风,但现场气氛丝毫未受到影响。
反倒是因为在24小时之前,OpenAI带着GPT-4o来了场截胡式官宣,把谷歌的这场I/O架在一个非常尴尬的位置,此刻大家似乎都在等着看谷歌“阁下又该如何应对”。
于是谷歌用了整场两小时的时间,来了场特种兵式的发布,一次性回应所有的声音。

如果用一个词形容今年的I/O,那一定是「全」,你能想到的几乎所有AI场景,谷歌这次都有涉及到:
从基础模型Gemini的性能增强(包括轻量级模型Gemini 1.5 Flash、200万tokens超长上下文的Gemini 1.5 Pro);到开源模型Gemma的进展(剧透下一代开源模型Gemma 2);到支持超过1分钟、1080P的视频生成模型Veo;与ChatGPT-4o一样“长了眼和嘴”的拥有视觉语音交互功能的Gemini Live;还有文生图模型imagen 3;AI音乐创作工具Music AI Sandbox;以及向其他AI Agent贴脸开大的Project Astra。

这么全,又这么多首发,很难不让人猜想,谷歌难道一直在憋大招?
留意到此前Madrona Venture Group合伙人、Amazon Web Services前人工智能高管Jon Turow说,谷歌这次的发布时间表较慢是可以理解的,因为谷歌 "比其他公司(如OpenAI)承担更大的责任",谷歌是在自家有着数十亿用户的现有业务上做文章,不是从零开始,所以更慎重。“当一个产品达到其他公司(如OpenAI)可以发布的标准时,谷歌也不能草率地发布。"
总之,“AI全家桶”这个名号,谷歌这次实至名归。
Gemini的完全形态:多模态、长上下文、AI Agent
当谷歌CEO桑达尔·皮查伊上台,好戏正式开始。

谷歌CEO桑达尔·皮查伊(Sundar Pichai)
“Gemini”“Gemini”“Gemini”这恐怕是整场出现频率最高的词,作为谷歌目前最核心的基础模型,Gemini尽显谷歌在AI时代的野心。
1年前,Gemini问世时谷歌对它定位就很明确:多模态模型。在那之后,Gemini就朝着该定位,开始火速迭代。去年12月,谷歌推出Gemini 1.0,共有三个版本:Ultra、Pro 和 Nano。两个月后,谷歌又推出Gemini 1.5 Pro,有了更强的性能、100万token的长上下文。
“谷歌正式迈向Gemini时代(Google is fully in Gemini era)”,皮查伊直奔主题说:
目前有超过150万开发者在工具中使用Gemini,有20亿用户产品在使用Gemini,而谷歌推出安卓和iOS上可用的Gemini Advanced在发布三个月后就已经收获超过100万用户。
此外,Gemini 1.5 Pro还从原本的100万token升级到200万token,这意味着能处理1500页PDF、3万行代码、或1小时视频文件,即日起Gemini 1.5 Pro将通过Gemini Advanced向全球150多个国家的用户正式推送,且支持35种语言。

Gemini 1.5的 200 万token能力横评对比
而在现场,Gemini又有更新:谷歌发布针对端侧的模型Gemini 1.5 flash,同样有100万和200万token版本。相比此前的Gemini 1.5 Pro,该模型的特点是轻量级:更快速高效、多通道推理、长上下文。
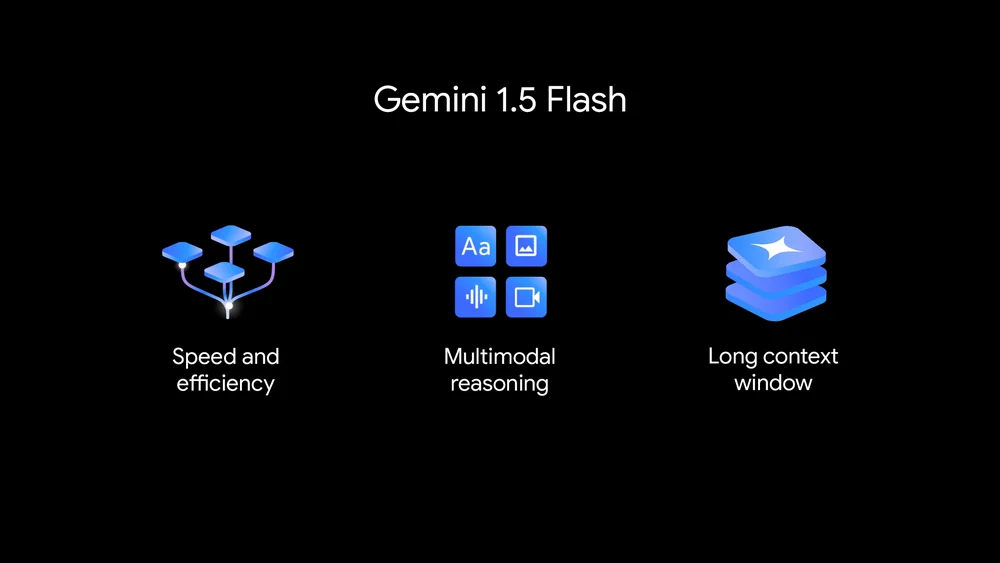
价格方面,Gemini 1.5 Pro为7美元/100万tokens,对于128k以下的输入,将降价50%至3.5美元/100万tokens,比 OpenAI 的 GPT-4o 便宜约 30%;Gemini 1.5 Flash的价格为0.35美元/100万tokens,比OpenAI的任何大模型都便宜。
除了Gemini本身的更新之外,更重要的是,谷歌把Gemini植入到所有产品中,包括搜索、地图、照片、Workspace、安卓等等。
· 搜索大不同
作为搜索巨头,要想让Gemini成长,谷歌自然不会放过搜索这个现成的数据库,所以,你现在在谷歌的每一次搜索,背后都有Gemini在工作。这个功能被称为「AI Overview(AI概述)」,是指AI会根据你的搜索,给出最佳答案,提升搜索体验。
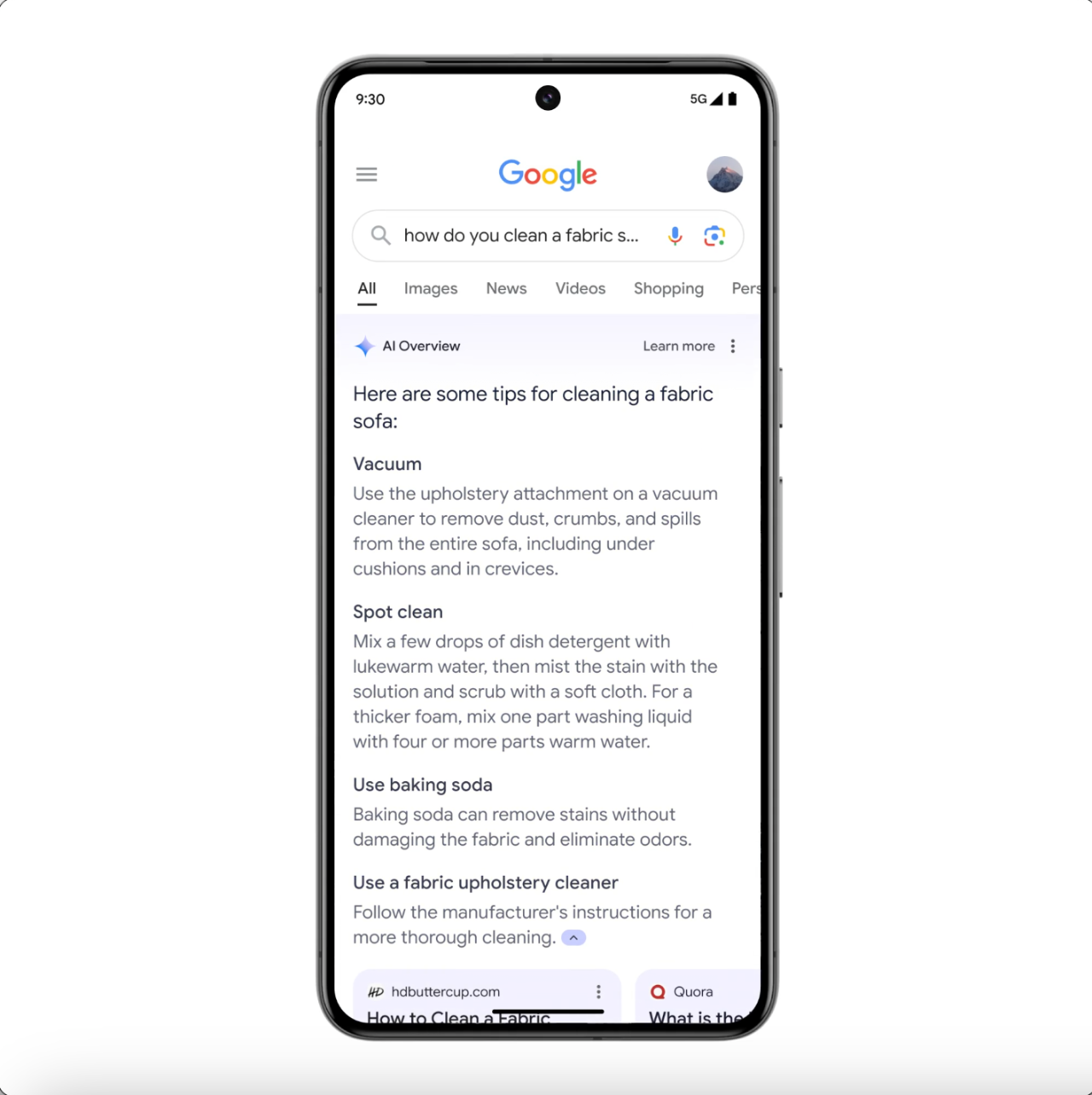
相比传统的搜索引擎,AI Overviews功能将为用户呈现出包括观点、见解、链接的完整答案。谷歌强调其三大独特优势:实时信息、排名和质量体系、Gemini能力。谷歌引入多步推理功能(Multi-step reasoning),把大问题一步步分解,并按优先顺序提供。
例如,用户想找一个合适的普拉提工作室,需要考虑时间、价格、距离等因素,就可以在谷歌搜索输入:“在波士顿找到最好的瑜伽工作室,并显示优惠详情,以及从我家过去的步行时间”。最终,谷歌搜索将提炼整合出信息,并呈现在AI Overviews中,为用户节省时间。
· 今夏上线的Ask Photos
当然,不仅谷歌搜索有Gemini,照片搜索中也有Gemini。皮查伊现场演示了Gemini在Google Photos(谷歌相册)里如何整活儿,比如你在停车场给车拍了照之后,找不到车停哪儿时,可以直接问 Gemini “我的车在哪”,它就能帮你自动识别相关照片中的信息,告诉你车的具体位置。
这个功能被称为「Ask Photos」,将于今年夏天正式发布。
而正是因为Gemini的多模态和“长”上下文,Ask Photos不仅能搜索照片,甚至能理解搜出来的内容。比如,你在回忆女儿Lucia的高光时刻,可以直接问Gemini:“Lucia是啥时候学会游泳的?”甚至问更复杂的问题:“Lucia的游泳进步了夺少?”
在这背后,Gemini可以根据“Lucia在游泳池里游泳,到在海洋里浮潜,再到游泳证书上的文字和日期”一系列内容,最后告诉你答案。
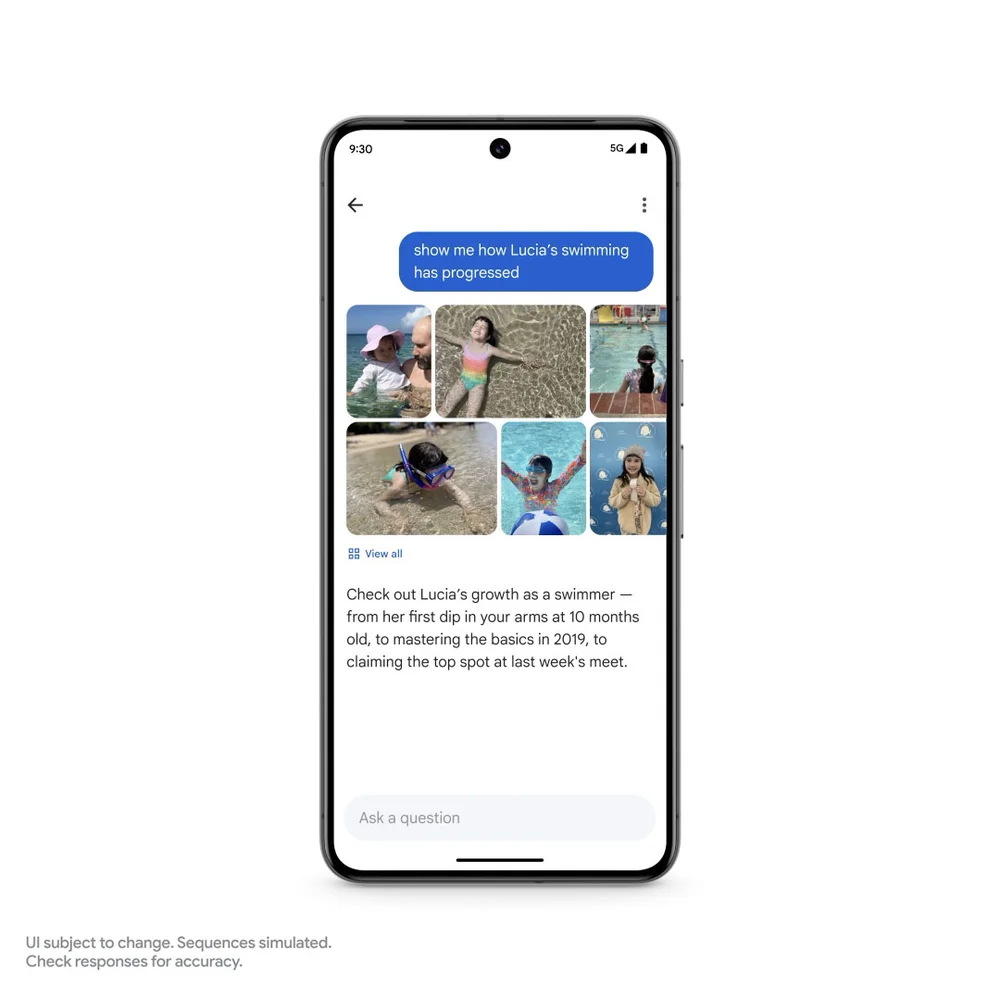
这一切,都是因为Gemini的两大能力——多模态+长上下文。“多模态可以解锁更多知识,并输出更多答案。而长上下文就能输入更多信息:数百页的文本,数小时的音频,1小时的视频,完整的代码库……甚至,如果你愿意,引入96个Cheesecake Factory菜单(编者注:美国的芝乐坊餐厅)也不是不可以。”皮查伊开玩笑说。
- 更智能的办公套件
有了上述俩特长,Gemini也被植入到谷歌的办公套件中。包括在Google Meet中生成会议纪要,在Gmail的所有邮件中提取关键信息,自动整理邮件中的表格,甚至生成一张数据分析表格。
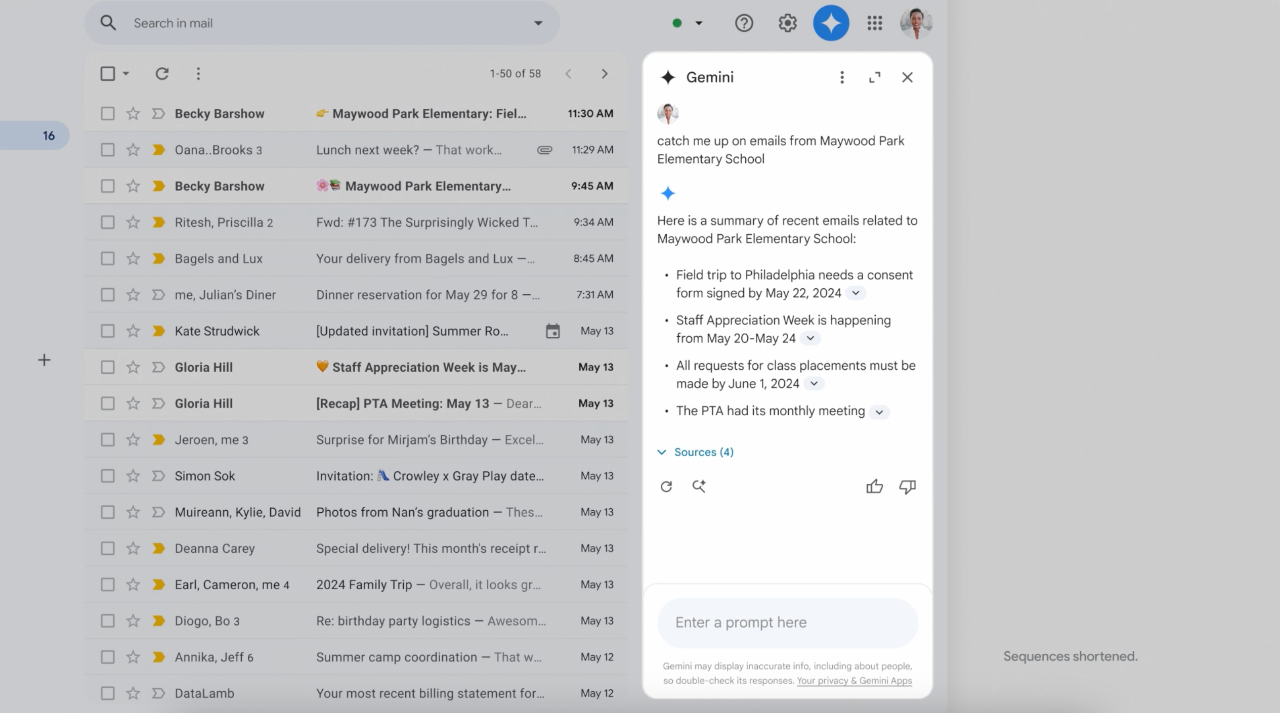
当然,仅仅是多模态+长上下文还不够,谷歌为Gemini注入了最后一股力量:AI Agent(AI智能体)。
皮查伊举了一个“网购”的例子。买鞋是件很有趣的事,但是当鞋子不合脚的时候,退货就没那么有趣了。而因为有了AI智能体,Gemini可以替你完成所有的退货步骤:在收件箱里搜索收据-从购买记录里找订单号-填退货单-安排快递上门取货,一气呵成。
至此,Gemini的终极形态初现——多模态、长上下文、AI Agent。
Project Astra扛大旗:看似Agent,实则通向AGI
第二位上场的嘉宾,作为AI界大神级的人物,Google DeepMind创始人Demis Hassabis首次出现在I/O的舞台上,收获了台下阵阵掌声。

Google DeepMind创始人Demis Hassabis
自从被谷歌收购之后,DeepMind早已成为谷歌的左膀右臂。去年,Google DeepMind实验室成立,将两家公司的AI人才整合,也收获了不少成绩,比如上周问世的用于预测几乎所有生物分子结构和相互作用的AlphaFold 3就是其中之一。
与现场高涨气氛相呼应的,Demis Hassabis的发布也相当轰动,其中就包括一个AI Agent(AI智能体)新项目——Project Astra。

从现场的演示视频来看,其中的一幕是,演示者拿着手机,让AI实时收集周边环境信息,然后在办公室转了一圈突然问:“你记得我的眼镜在哪里吗?”只见它立刻回答:“记得,在桌子上的红苹果旁边。”
要知道,在实际场景中,哪怕两个人类对话,也可能会忽略这些细节,但演示中的AI却精准捕捉到了眼镜的位置。这种强大的通用语言与环境理解能力,瞬间让现场响起雷鸣掌声。
Hassabis特别提到,这些演示并非“仅供参考”的演示效果,都是在一次性拍摄中实时捕捉。他坦言,其中最受挑战的是“将响应时间缩短为对话式的内容”,为此,DeepMind在Gemini的基础上开发了原型Agent,通过连续编码视频帧、将视频和语音输入组合到事件时间线中并缓存,以确保能快速有效调用,从而更快地处理信息。
“过去几年里,我们一直在改进模型的感知、推理和对话方式,使交互的速度和质量更自然。”Hassabis说,有了Astra项目,大家未来可以在手机或眼镜上拥有专业的AI助手。
伴随着Astra的发布,Hassabis也强调了他们的最终目的——AGI。“计算机能像人一样思考,这件事从小就让我着迷,这也是我研究神经科学的原因,2010年我创办DeepMind时,终极目标就是AGI,我相信如果负责任地开发这项技术,它对人类的影响将会是无比深远的。”
当然,除了对AGI的探索之外,谷歌还介绍了在多模态领域的新进展,从图像、到音频、到视频这三个主要内容源全面出击:包括能够生成超过1分钟、1080P 的视频生成模型Voe、文生图模型Imagen 3、以及面向专业音乐创作者的AI音乐创作工具 Music AI Sandbox。

由谷歌的文生图模型Imagen 3生成
从Voe的演示视频来看,它能理解很多电影术语,如“延时”“景观航拍”“时光倒流(Timelapse)”。谷歌指出,Veo 建立在多年的生成视频模型的基础上,包括生成查询网络(GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere,以及Transformer 架构和Gemini。未来,谷歌还将把Veo的一些功能引入YouTube Shorts和其他产品。
而在AI音乐创作方面,谷歌通过Music AI Sandbox跟音乐家合作,音乐家可以把一段哼唱或弹奏的灵感片段发给AI,AI生成一首歌或旋律。
有“软”也有“硬”
作为专门面向开发者的I/O,除了软件的密集发布之外,硬件的同步更新也一直是I/O的保留项目。
这次,谷歌发布了第六代 TPU 硬件Trilium,计算能力相比前代提升 4.7 倍,预计将在 2024 年底面向用户推出,谷歌这次发布的Veo、Imagen 3、Gemini 1.5 Pro 等几乎所有产品,都是基于这款新硬件。

十多年前,谷歌就意识到,需要一款用于机器学习的芯片。2013年,谷歌开始开发世界上第一款专用AI加速器TPU v1,随后在2017年推出了第一个云TPU。如果没有TPU,谷歌大量的服务(如实时语音搜索、照片对象识别、交互式语言翻译),以及最先进的基础模型(如Gemini、Imagen和Gemma)将不可能实现。
当然,除了硬件,安卓系统也不能忽略,尤其是 Gemini 的融入,是否会让安卓系统焕然一新?
这次 Gemini 在 Android 上的最新进展是——Gemini Live,主打一个用文本、语音或影像等多模态的交互体验,在实际对话过程中,你甚至可以像与真人对话一样,通过打断对话、提出新问题的方式来更高效的沟通。并且,谷歌透露,基于 Project Astra 实现的摄像视频识别功能也将在今年年内发布,所以用户可以打开摄像头,让AI看见周围的世界并做出实时响应。
在演讲接近尾声时,皮查伊提到此前I/O玩过的一个旧梗:“今天肯定有人数,我说了多少次AI?”。
“不用数了,因为Gemini数完了。”他接着说。
然后大屏幕显示120次。

“我竟然说了这么多次AI。”皮查伊笑道。
在皮查伊说出这句话的同时,屏幕上的数字变成了 121。
现场笑声一片。
整场围观下来,此次I/O密集的发布,与其被网传的说是竞争压力下的紧迫感,不如看成是面向AI变革下的一种随时准备好的从容。
在这场活动结束的数小时后,谷歌玩了个“AI点评AI”:
谷歌用刚刚发布的Astra,解说此前OpenAI发布会上现场演示的ChatGPT-4o。(也就是用谷歌的AI去评判OpenAI的AI)
从视频来看,效果拉满。Astra站在上帝视角,作为观察者,准确解读了被观察者ChatGPT-4o的动作,预判后者行动。
最有意思的来了,当01分02秒时,Astra提前解出方程,然后说,“让我们看ChatGPT-4o能不能算出来”(带着傲娇气),不过,接下来在02分20秒时,Astra又开启了夸夸模式,把气氛拉了回来。
看完之后,一句话出现在我的脑海里:
“人类总是互相竞争,但AIs help AIs?”


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升

周雅
主编
