 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
刚刚,谷歌带来“量子回声”算法突破,AI算力的下一个增长曲线在浮现?

作者 | 周雅
假如,你正在深邃的海底找一艘历史沉船,传统的声纳技术或许能给你一个模糊的轮廓,然后告诉你:“那下面有艘沉船”,但如果有一种技术,不仅能让你准确定位到这艘船,还能让你读清船身上那块饱经沧桑的铭牌呢?
这是谷歌量子芯片Willow所达到的精度。就在刚刚,谷歌量子AI团队宣布了一项重要突破,通过运行“out-of-order time correlator(OTOC)”算法,证实了“首个可验证的量子优势”,并为它赋予了一个形象的名字:“Quantum Echoes”(下文译作“量子回声”)。这项研究成果同步发表在《自然》杂志上。
科技行者TechWalker受邀参加了此次发布的视频简报会。谷歌量子AI团队对外传播主管Alison Carroll在会上强调:“量子回声算法,标志着量子计算迈向实际应用的一大步。”

这里有必要讲讲这次发布的背景:
2019年,谷歌的超导量子芯片Sycamore仅用200秒就完成了一项计算,而世界最快的超级计算机需要1万年,当时被谷歌CEO桑达尔·皮查伊(Sundar Pichai)称作是“莱特兄弟12秒的首飞”。
到了2024年底,谷歌的量子芯片Willow在量子纠错方面取得了新进展,首次实验证明了可以通过增加量子比特规模来指数级地抑制错误,解决了困扰科学家近30年的一个重大难题。
但整个行业都在追问:量子计算机除了能解决数学难题之外,到底还能做啥?怀疑论者认为它可能只是一个实验室玩具,乐观者则在等待那个“杀手级应用”的到来。
那么此次谷歌的发布,就是回应。

为何要造量子计算机?
或许很多人好奇,谷歌费这么大劲造量子计算机,图啥?谷歌量子AI团队创始人哈特穆特·奈文(Hartmut Neven)直言:“量子计算机可以解决经典超级计算机或运行在经典超级计算机上的AI都无法解决的问题。”
他引用加州理工学院物理学教授约翰·普雷斯基尔(John Preskill)的观点来定调:“量子计算机不仅是传统计算机的加强版,它以截然不同的方式处理信息,因为它遵循微观世界的量子力学原理”。
奈文说,量子计算机最厉害的应用,就是帮我们搞科学发现,比如药物研发、材料科学,这些都涉及到研究微观世界里的分子。经典计算机在模拟这些分子时,尽管功能强大,但也只能算个大概,不能精确描绘出分子世界中到底发生了什么。
但量子计算机不一样,因为它本身就是用量子的方式工作的,所以它能“说”微观世界的语言。所以它不是在“模拟”自然,而是在用自然本身的法则去“复现”自然。就好比让一个本地人给你介绍家乡,信息绝对地道。
这个愿景,激励了一代代科学家。奈文特别提到了刚刚拿到诺贝尔物理学奖的米歇尔·德沃雷(Michel Devoret),他是谷歌量子AI量子硬件首席科学家。在1980年代,德沃雷与约翰·克拉克(John Clarke)、约翰·马丁尼斯(John Martinez)组成的三人组,首次造出了“人造原子”——这正是今天超导量子比特的雏形。正是这些基础研究,为后来的量子计算硬件发展奠定了基石。
现在AI这么火,量子计算能跟它能擦出什么火花?
奈文说,量子计算与AI是“双向奔赴”的关系:一方面,以后量子计算机能让AI变得更强。另一方面,谷歌现在已经在用AI来帮助设计量子计算机,像开篇提到的谷歌新突破“量子回声”就是例证。
但奈文强调了一个更酷的玩法:量子计算机可以成为AI的超级“数据工厂”。他解释说:“AI的学习离不开数据,而我们生活的物理世界本质上是量子的,所以量子计算机可以生成独特且有价值的量子数据,喂给AI去学习。”
为了便于理解,奈文在采访中举了一个例子。他提到在预测蛋白质三维结构方面取得巨大成功的AI模型(如AlphaFold),这些模型的成功,很大程度上依赖于一个名为“蛋白质数据库”(Protein Data Bank)的关键数据集。但是这个数据库的建立,始于1970年代,是科学家们花了整整50年才辛辛苦苦积累起来的。奈文说:“有了‘量子回声’这样的算法,我们制造这种高质量数据的速度会快得多!对于推动AI的发展极其有价值。”

里程碑之路:从“量子优势”到“可验证的量子优势”
要理解“量子回声”的突破性,我们必须回顾谷歌量子AI团队的征程。奈文在去年的媒体沟通会上曾分享愿景:“当我们于2012年创立谷歌量子AI团队时,愿景是构建一个有用的大规模量子计算机,利用我们今天所知的量子力学(自然界的‘操作系统’)来推动科学发现、开发有益的应用、并解决一些社会的关键挑战。”
这条路分为几个关键阶段:
第一个里程碑(2019年):量子优势(Quantum Supremacy)。53量子比特的Sycamore芯片在200秒内完成的“随机线路采样”(RCS)任务,当时最强的超级计算机需要10000年。这证明了量子计算机在特定问题上超越经典计算机的可能性,但RCS本身并无直接的实际应用。
第二个里程碑(2024年):量子纠错(Quantum Error Correction)。Willow量子芯片,在谷歌自家的专用超导芯片制造工厂中诞生,解决了量子计算的“阿喀琉斯之踵”——错误。物理量子比特极其脆弱,通常数量越多,错误也越多。但Willow首次实验证明,通过构建更大的逻辑量子比特(如从3x3扩展到7x7的物理比特阵列),错误率可以被指数级地压制。
这一“低于阈值”的突破,证明了构建大规模、可靠的容错量子计算机在物理上是可行的。同时,在RCS基准测试中,Willow将与经典超算的差距拉大到了宇宙尺度——不到5分钟的计算,最快的Frontier超级计算机需要10^25年。奈文提到,这表明,通过构建更大的量子系统,有望抑制错误,为构建大规模容错量子计算机铺平了道路。
而今天的突破,则属于应用落地层面的里程碑:第一个超越经典计算机能力的有用算法——“量子回声”算法,它的核心特质在于——“可验证的量子优势”(Verifiable Quantum Advantage)。
那么,“可验证的量子优势”究竟意味着什么?奈文将其拆解为几个关键特点:
首先,是运行起来更快。经典超级计算机Frontier需要3.2年才能完成的计算,量子计算机仅用2.1小时就搞定,速度快了13000倍。
其次,是实现了“可验证的量子优势”(Verifiable Quantum Advantage)。这也就对应了费曼的预言——量子计算机能够对自然系统做出经典机器无法企及的预测。
“可验证”这个词,是理解本次突破的钥匙。它意味着量子计算的结果,不再是某种概率性的、难以捉摸的“黑箱输出”,而是可以被重复检验、被信任的可靠数据。奈文解释说,“验证”可以通过两种方式进行:一是在另一台(同等级别的)量子计算机上重复计算,看是否得到相同的结果;二是通过自然本身来验证,即进行一个真实的物理实验,看预测是否与实验结果相符。
最后的特点是,为真实世界的应用打开大门。在另一项名为《通过多体核自旋回声实现分子几何的量子计算》(Quantum computation of molecular geometry via many-body nuclear spin echoes)的概念验证实验中,谷歌展示了如何通过新技术——“molecular ruler”——能够测量比现有方法更长的距离,利用核磁共振(NMR)数据获取更多关于化学结构的信息,这具有巨大的现实应用潜力。

揭秘“量子回声”:让时间“倒流”来获取信息
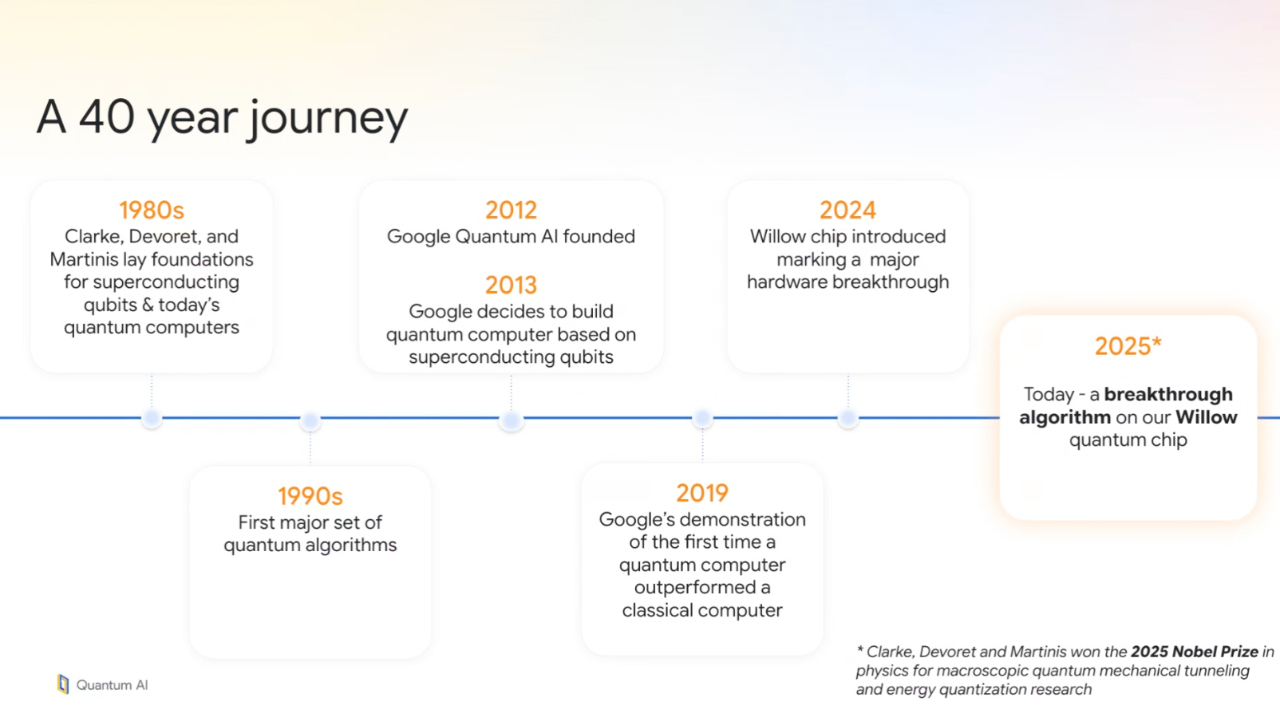
那么,这个神奇的“量子回声”算法到底是怎么工作的?谷歌量子AI团队研究科学家Xiao Mi用这样一个绝妙的比喻解释它的原理:
他说,传统的量子算法就像你拿个喷枪往前喷水,水滴一下子就散开了,很难收集。但“量子回声”不一样,它在把水喷出去之后,又在前面放了面“镜子”,让所有水滴都反弹回来,重新汇聚在一起。这样,你就能从反射回来的“回声”中捕捉到大量信息。
技术上讲,这个算法就是先把一个量子过程“正着放一遍”,然后再“倒着放一遍”。在正放和倒放之间,他们会故意轻轻“戳”一下系统里的某个量子比特,就像往平静的湖面丢一颗小石子。最后,通过分析那个“回声”的强度和形状,就能极其精确地知道这次“轻戳”在系统里引起了怎样的涟漪,从而揭示出系统内部的秘密。
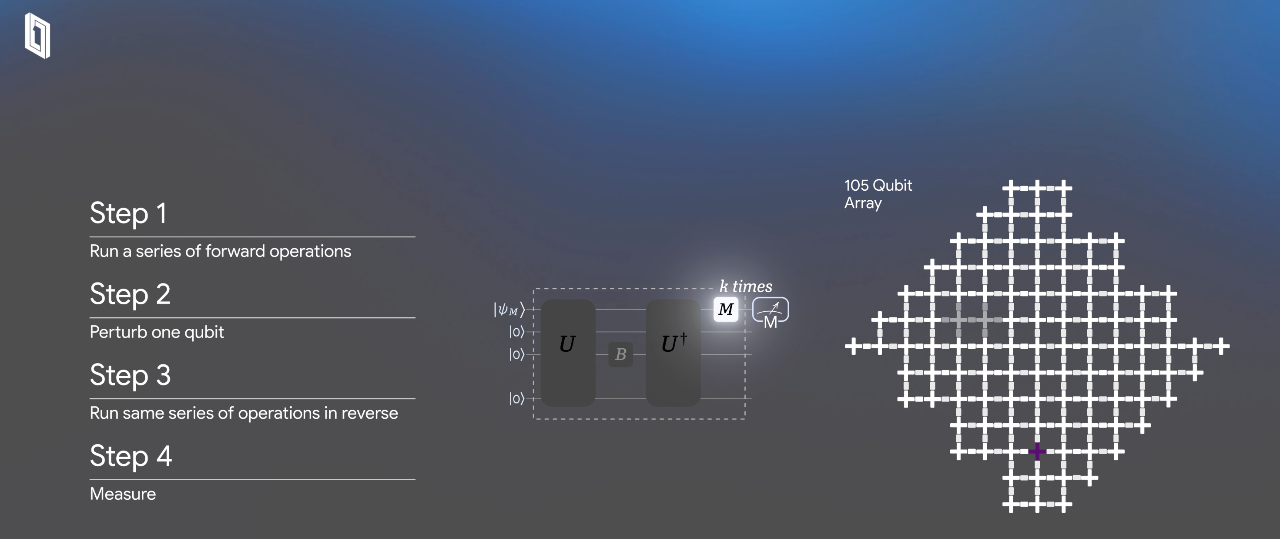
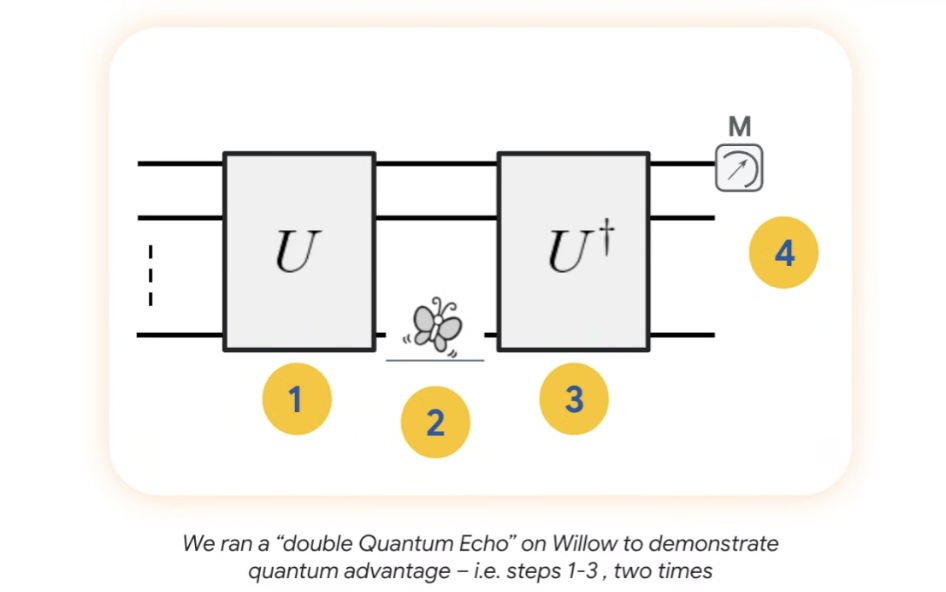
如图所示,U(向前演化)和U†(向后演化)两个操作块,而夹在两者之间的一个“小小的蝴蝶符号”,本质上是谷歌团队故意在某个量子比特上注入的一个微小扰动,以便在序列结束时揭示出关于量子系统的有用内容。
这个过程之所以厉害,一来,因为它能把微小的细节放大,向前和向后演化的轨迹会相互交织,产生极其复杂的干涉图样,这个图样对量子系统内部的细节极为敏感,使最终测量到的“回声”信号包含了异常丰富的信息;二来,正是这种干涉的复杂性,让经典计算机根本模仿不来,这正是它能实现量子加速的关键。
当然,一个好算法,必须要有强大的硬件支持。Xiao Mi强调,这项工作完全依赖于过去几年谷歌在量子硬件上的重大进步,尤其是Willow量子芯片的卓越性能。
它究竟对硬件的要求有多高?Xiao Mi做了一个强烈的对比:
六年前,谷歌搞了第一个成功击败经典计算的实验(即“量子优势”实验,那时候叫做“随机线路采样”),要求很低,从量子计算机里得到的数据,只要有0.1%是正确的就算成功。
而今天这个“量子回声”实验,要求极高,你只能犯0.1%的错误,也就是说,从硬件收集到的绝大部分量子数据都必须是正确的。
从“允许99.9%的错误”到“要求99.9%的正确”,这简直是天壤之别。Xiao Mi明确表示:“如果没有过去几年芯片精度的提升,这根本不可能做到。”
除了极高的保真度(低错误率),芯片的速度也很重要。“Willow速度非常快,可以在微秒量级的时间内运行量子算法,在几秒钟内完成数百万次测量。”Xiao Mi说,这让团队可以像训练AI一样,反复试验,从海量的结果中优化算法参数,逐步找到最佳方案。他透露,为了优化这个算法,团队总共进行了将近一万亿次的测量。
走向实用:一把能看得更远的“分子尺子”
说了半天理论,这东西到底能干嘛?谷歌量子AI团队首席运营官Charina Chou将话题引向了此次发布的核心——量子芯片在真实世界里的应用。
团队选择的第一个应用场景,是帮我们更好地使用“核磁共振(NMR)”技术。你可能不了解NMR,它是已经存在了大约80年、催生了无数诺贝尔奖的强大分析工具,在药物研发和材料科学中至今仍扮演着核心角色,功能是帮助科学家理解分子的结构。比如,医院里的核磁共振(MRI)检查就是基于它。
Charina Chou说,NMR中的“量子回声”在这里扮演的角色,就像一把“分子尺子”,而且这是一把能量得更远的尺子。她说,现有的NMR技术虽然厉害,但在测量分子里相距较远的两个原子时,就有点力不从心了。而“量子回声”正好能解决这个问题。
为了证明这一点,谷歌和加州大学伯克利分校Pines Lab磁共振中心等机构的专家们做了个实验:
第一步,把两种真实的分子放进一台NMR机器里。
第二步,用Willow量子芯片来模拟和分析NMR机器产生的复杂信号。
结果发现,他们不仅验证了已知的分子信息,还发现了一些以前看不到的、关于分子内部的新信息。
Charina 总结说,望远镜和显微镜让我们看到了前所未见的世界,而“量子回声”就像一个“量子镜”(quantum-scope),能帮我们揭示从前无法观察到的微观结构和分子结构。
量子计算之路无法单打独斗
在量子计算这么复杂的领域,单打独斗是行不通的。Charina 特别强调了谷歌的开放合作态度。
她明确指出,NMR应用之所以可能实现,得益于与加州大学伯克利分校、达特茅斯学院、Google DeepMind、Q-Simulate公司等多个合作伙伴的协作。她说,“谷歌虽然在量子计算方面很强,但我们不是所有领域的专家,这是一个全球性的努力,没有哪个公司或国家能单凭自己搞定量子计算机和它所有的应用。”
为了践行开放合作理念,谷歌采取多管齐下的策略:
首先是开源。把自己的软件、代码和论文都公开,让全世界的研究者都能用,谷歌甚至在Coursera等平台上开设关于量子纠错的课程,以促进整个社区的发展。
其次是广泛合作。谷歌量子AI与来自各个机构、学术界和政府的超过100个组织建立了合作关系。
最后是共享硬件。通过一个名为“量子硬件驻留计划”(Quantum Hardware Residency Program)项目,谷歌甚至为特定的研究人员提供直接访问Willow芯片进行实验的权限,以激发更多来自外部的创新。
当被问及如何看待竞争时,Charina 坦言,就像经典计算机一样,最好的应用创新往往来自更广阔的世界,与其把技术藏着掖着,不如开放出来,让大家一起来探索它的无限可能,这也是谷歌期待看到的。
通往终极目标:5年之约和百万量子比特
在问答环节,一个备受关注的问题是,通往真正实用的量子计算机,还需要哪些突破?
奈文重申了团队的乐观预测:“五年内,我们就能看到只有量子计算机才可能实现的真实世界应用。”而量子回声的成功,无疑增强了这种乐观情绪。不过奈文也指出,“量子回声”算法是在现有的NISQ芯片上实现的,这些芯片的量子比特数量尚不足以进行完全的算法级纠错。
那么,未来需要什么?奈文描绘了终极目标——一个终极版的容错量子计算机,也就是去年谷歌透露的“谷歌量子计算路线图”中的第6个里程碑。奈文描绘了这台机器的样子:要解锁更多应用,需要一台拥有约100万个“物理量子比特”的机器,其错误率至少为10的负9次方(意味着量子计算机在进行1,000,000,000次运算或操作时,平均只会出一次错),通过复杂的纠错技术,组合成大约1000个超级稳定、几乎不出错的“逻辑量子比特”。
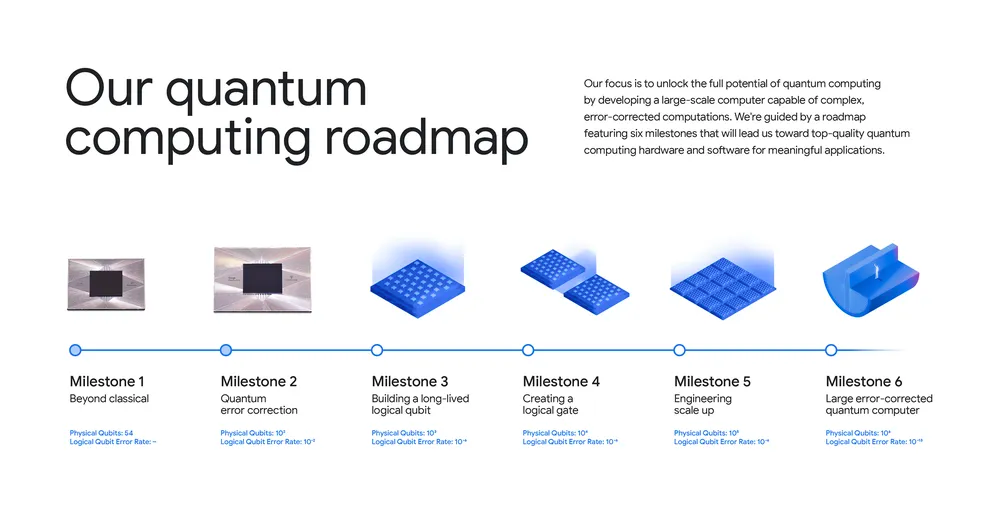
谷歌量子计算路线图
简单打个比方,物理量子比特就像一群有点粗心、容易犯错的工人。而逻辑量子比特,就是把一群粗心的工人组织起来,让他们互相检查工作,从而组成一个极其可靠的施工队。所以,你需要很多“工人”(100万),才能凑出足够多的高水平“施工队”(1000个)。要达到这个目标,既要增加工人的数量,也要提高每个工人的技术水平(降低错误率)。这再次印证了谷歌一直以来强调的“质量与数量并重”的路线。
关于功耗问题,Charina给出了当前的数据:“目前的量子计算机耗电量跟一个服务器机柜差不多。” 奈文估算,未来百万量子比特的巨型机,可能需要一个小型发电站来供电。这或许暗示了未来大规模量子计算中心可能面临的能源挑战。
最后当被问及“在量子计算时代,谷歌的服务会是什么样子”时,奈文认为,量子计算将以特定的方式增强现有服务,比如为Gemini这样的基模提供更好的训练集。他重申了量子计算作为“数据生成器”对于AI的价值,这一协同进化正在发生。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升

周雅
主编
