 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
Gmail加强安全:若用户被政府监控可收到警告

北京时间3月25日消息,苹果并不是唯一一家与美国政府的间谍攻击做斗争的科技公司。正当苹果与FBI的官司广受瞩目时,谷歌也在以自己的方式加强自身服务的安全性——他们会直接把情况告知用户。
该公司将通过警告的方式加强Gmail的安全性,希望以此帮助用户在收发电子邮件时更好地采取自我保护措施。
其中一项变化是扩大“安全浏览”通知的范围,这项功能可以在用户从电子邮件中打开可疑链接时发出提醒。当用户点击某个可以链接后,系统便会在该链接真正打开前发出提醒信息,要求用户最终确认是否打开该链接。
在此之前,这种链接只会出现在用户尚未点击链接前。倘若用户没有看到链接,便不会再次发出警告。谷歌希望通过这种额外的警告帮助用户避开恶意网站。
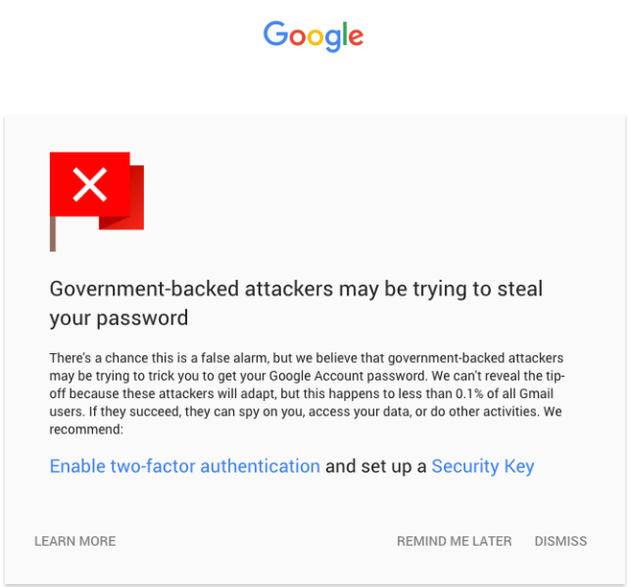
除此之外,谷歌还将继续与政府支持的攻击行为展开斗争。当系统发现有政府支持的黑客正在监控用户时,便会展示一条全屏警告信息。谷歌曾经在官方博客中表示,只有不到0.1%的Gmail用户会收到这种警告,但由于看到这一警告信息的往往是记者、政策制定者和激进人士,使得这种警告变得尤为重要。
这种新的警告方式有可能与现有的警告共存,也有可能取代现有的模式。
谷歌最近一直在加强Gmail的安全性,该公司上月还宣布将向没有使用TLS加密技术的用户发送邮件。谷歌表示,自从发出这封邮件以来,使用加密连接发送的电子邮件数量增加了25%。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
